키-값 저장소 설계 가이드: 개념부터 아키텍쳐까지
⚡ TL;DR (Too Long; Didn’t Read)
키-값 저장소(Key-Value Store)는 대규모 시스템에서 빠른 데이터 접근을 위해 필수적인 NoSQL 데이터베이스 유형이다. 이 글에서는 키-값 저장소의 개념, 설계 고려 사항, CAP 이론, 샤딩 및 복제 전략, 장애 처리, 시스템 아키텍처를 상세히 다룬다.
✔ 일관성 vs. 가용성 선택법
✔ 샤딩과 안정 해싱(Consistent Hashing) 전략
✔ 정족수 합의(Quorum)와 데이터 버저닝 기법
✔ 실제 서비스에서 활용하는 키-값 저장소 구조
이 글을 읽으면 고성능 분산 시스템에서 키-값 저장소를 어떻게 활용할지 이해할 수 있다! 🚀
1. 키-값 저장소란?
키-값 저장소(Key-Value Store)는 데이터를 키(key)와 값(value)의 쌍으로 저장하는 비관계형(NoSQL) 데이터베이스의 한 유형이다.
빠른 읽기/쓰기 속도가 필요한 대규모 시스템에서 널리 사용된다.
✅ 주요 특징
- 단순한 데이터 모델: 키를 통해 값을 저장하고 검색하는 구조.
- 빠른 조회 성능: O(1)에 가까운 조회 속도
- key를 통해 탐색하기 때문에 key=value는 1:1 구조
- 성능 상의 이유로 key는 짧은 것이 좋기 떄문에 hash key를 사용하는 경우가 많다.
- 수평 확장 용이: 샤딩(Sharding)과 파티셔닝(Partitioning)을 통해 쉽게 확장 가능.
- RDMS와 같이 복잡한 관계구조가 없기 때문에, 데이터가 여러 서버에 분산되어도 독립적 동작 가능 (데이터 의존성 낮음)
- 해시 기반 샤딩, 파티셔닝이 가능하여 데이터 분배 쉽고, 논리적 데이터 관리 가능
- 안정 해시(consistent hashing) 사용 시, 노드 추가/삭제 시 데이터 이동 최소화 가능
- 일반적인 사용 사례:
- 캐싱 (예: Redis, Memcached)
- 세션 저장 (예: 로그인 상태 관리)
- 구성 데이터 저장 (예: 환경 변수, 설정 값)
2. 키-값 저장소 설계 고려 사항
2.1 데이터 저장 방식
- 메모리 기반 저장소
- 초고속 접근 가능하지만, 메모리 제한이 있음.
- 주로 캐싱 용도로 사용.
- Redis: 세션 저장, 랭킹 시스템, 메시지 큐 등.
- Memcached: 웹 애플리케이션 캐시, 데이터베이스 쿼리 결과 캐싱 등.
- 디스크 기반 저장소
- 대량의 데이터를 영속적으로 저장 가능.
- 성능 최적화를 위해 LSM-Tree(로그 구조 병합 트리)나 B-Tree 활용.
- RocksDB, LevelDB: 대량의 데이터 저장 (예: 로그, 분석 데이터, Key-Value Store)
2.2 일관성(Consistency) vs. 가용성(Availability)
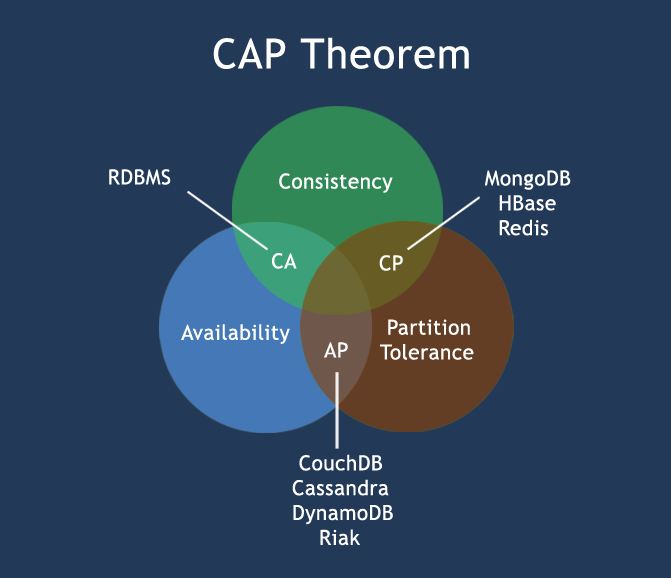
CAP 이론에 따라 설계 방향이 달라진다.
📚 CAP 정리
- Consistency : 데이터 일관성 - 어느 노드든 언제나 같은 데이터를 보장
- Availability: 데이터 가용성 - 일부 노드 장애 시에도 항상 응답을 전송
- Partition Tolerance: 파티션 감내 - 두 노드 사이에 통신 장애 발생, 네트워크 파티션 발생 시에도 시스템 계속 동작
세 가지 요구사항을 동시에 만족하는 분산 시스템 설계는 불가능하기에, 이들 가운데 두 가지 충족 시 나머지 하나는 반드시 희생되어야 한다.
하지만 분산 시스템에서는 반드시 파티션 문제를 감내해야 하기 때문에 분산시스템에서는 CA 시스템은 고려하지 않는다.
즉,
CP(일관성)과AP(가용성)사이에 하나를 선택해야 한다.
일관성 중심: 강한 일관성(Strong Consistency)- 🧐:”정확한 답이 아니라면 주지 않을께! 조금만 기다려줘!”
- 모든 노드에서 동일한(최신) 데이터를 읽을 수 있도록 보장
- 네트워크 지연으로 인한 성능 저하 가능성 (예: Paxos, Raft 사용).
- 금융 서비스, 결제 시스템과 같은 정합성이 중요한 시스템에서 사용.
- 💡 예제:
- A가 100원을 송금했을 때, B가 즉시 조회하면 반드시 100원이 입금된 상태여야 함.
- “무조건 최신 데이터를 보여줘야 하니, 조금 기다려!”
가용성 중심: 최종 일관성(Eventual Consistency)- 😀: “일단 빨리 응답을 줄게! 하지만 최신 정보는 아닐 수도 있어. 정합성은 나중에 맞출게!”
- 일단 응답을 빠르게 주지만, 데이터가 동기화되지 않았을 수도 있음.
- 일정 시간이 지나면(몇 초~몇 분) 결국 모든 노드가 동일한 데이터를 가지게 됨.
- 읽기 성능이 중요하고, 최신 데이터가 반드시 필요하지 않은 경우 적합. (예: 소셜 미디어, 메시지 큐, 로그 저장소)
- 💡 예제:
- 인스타그램에서 A가 새 게시물을 올리면, B는 바로 볼 수도 있고 몇 초 후에 보일 수도 있음.
- “최신 게시물이 바로 안 보일 수도 있지만, 곧 동기화될 거야!”
2.3 데이터 파티션(Partitioning)
샤딩(Sharding): 데이터를 여러 노드에 분산하여 저장하는 방식.
- 해시 기반 샤딩:
hash(key) % num_shards방식으로 키를 균등하게 분산. - 범위 기반 샤딩: 특정 키 범위를 기반으로 데이터를 분할.
- 안정 해싱(Consistent Hashing): 노드 추가/제거 시 데이터 이동을 최소화.
- Auto Scaling: 데이터가 많으면 서버 자동 추가/삭제되도록 할 수있다.
- 가상노드: 데이터가 서버마다 고르게 분산되어 안정적 운영이 가능하도록, 서버주소를 가지고 있는 가상노드를 분포시킨다.
- 해시 기반 샤딩:
장점: 시스템 확장성 증가, 단일 노드 부하 감소.
2.4 데이터 다중화(Replication)
- 높은 가용성과 안정적 확보를 위해 데이터를 N개 서버에 비동기적으로 다중화 필요
- 단, 가상노드 사용 시
데이터가 저장된 노드의 수보다실제 저장된 서버의 수가 작을 수 있다.- 데이터 저장 노드가 3개인데, 사실 그 중 2개는 같은 서버를 보고 있다면 사실 2개의 서버에 저장되어있어 분산이 잘 되지 않았음
- 안정성 담보를 위해
- 데이터 센터 분리: 데이터 사본은 다른 센터의 서버에 보관
- 센터들은 고속 네트워크로 연결
2.5 데이터 일관성과 비일관성 문제 해소
키-값 저장소에서 데이터 일관성을 보장하는 방법은 여러 가지가 있다. 하지만 완벽한 강한 일관성을 유지하면 속도가 느려지기 때문에, 정족수 합의(Quorum)와 데이터 버저닝 같은 기법을 활용하여 일관성을 유연하게 조절한다.
✅ 정족수 합의(Quorum) 기반 접근
키-값 저장소에서 데이터를 읽고 쓸 때, 여러 개의 복제본 중 일부만 확인해도 된다는 개념이다. 이를 통해 최신 데이터 보장과 성능을 조절할 수 있다.
Quorum 공식
1
2
3
N = 전체 복제본 수
W = 쓰기를 보장해야 하는 노드 수
R = 읽기를 보장해야 하는 노드 수
- 강한 일관성 모델 : W+R > N
- 느슨한 일관성 모델: W+R <= N (
최종일관성 모델도 이에 포함)
✅ 데이터 버저닝: 버전 관리로 충돌 해결
데이터 다중화 시, 가용성은 높아지지만 일관성이 깨질 수 있다.
- 버저닝
- 데이터를 변경할 때 마다 해당 데이터의 새로운 버전을 부여해서 가장 최신 데이터를 선택하는 방식이다.
- 버전 충돌(같은 버전으로 동시에 변경됨) 시, 충돌을 발견하고 자동으로 해결하기 위한 버저닝 시스템이 필요하다.
- 벡터 시계
- 버전 충돌 문제를 해결하기 위해 사용되는 기술이다.
- 각 노드가 데이터를 변경한 시간을 추적하는 방식을 통해, 충돌 여부를 확인하고 해소할 수 있다.
2.6 장애 처리(Fault Tolerance)
장애 감지
장애 감지를 위해 모든 노드 사이에 멀티캐스팅 채널을 구축한다.
가십 프로토콜(분산형 장애 감지 솔루션) 채택!
- 각 노드 마다 멤버십 목록(다른 노드들에 대한 정보를 멤버십으로 등록)을 가지고 있는다.
- 주기적으로 노드들은 자신의 박동 카운터를 증가시킨 후, 본인의 박동 카운트를 무작위의 노드들에게 보낸다.
- 멤버십 목록에서 박동 카운트가 지정된 시간동안 갱신되지 않으면, 해당 멤버는 장애 상태로 간주된다.
장애 처리
일시적 장애처리
- 엄격한 정족수 접근법이라면 특정 서버 장애 시 읽기와 쓰기 연산을 금지한다.
- 느슨한 정족수 접근법이라면 특정 서버 장애 발생 시, 다른 건강한 서버에서 장애가 발생한 서버의 역할을 대신한다.
- 그 후 복구가 되면 그 때 그 동안의 변경 내용을 복구된 서버에 반영한다. (=> 단서 후 임시 위탁)
영구 장애 처리
반엔트로피 프로토콜 구현: 사본 동기화
머클 트리 사용!
![머클트리(Merkle tree)란?]
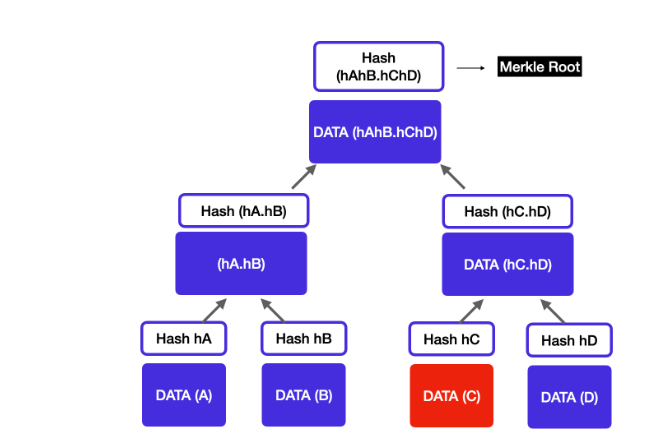
- 머클 트리는 데이터를 해시(Hash) 함수로 변환하여 트리 형태로 저장하는 구조
- 루트 해시값을 비교하여, 다르면 하위 루트로 내려가 다른 데이터를 찾아내서 해당 버킷의 데이터만 동기화하면 된다.
3. 키-값 저장소 시스템 아키텍쳐
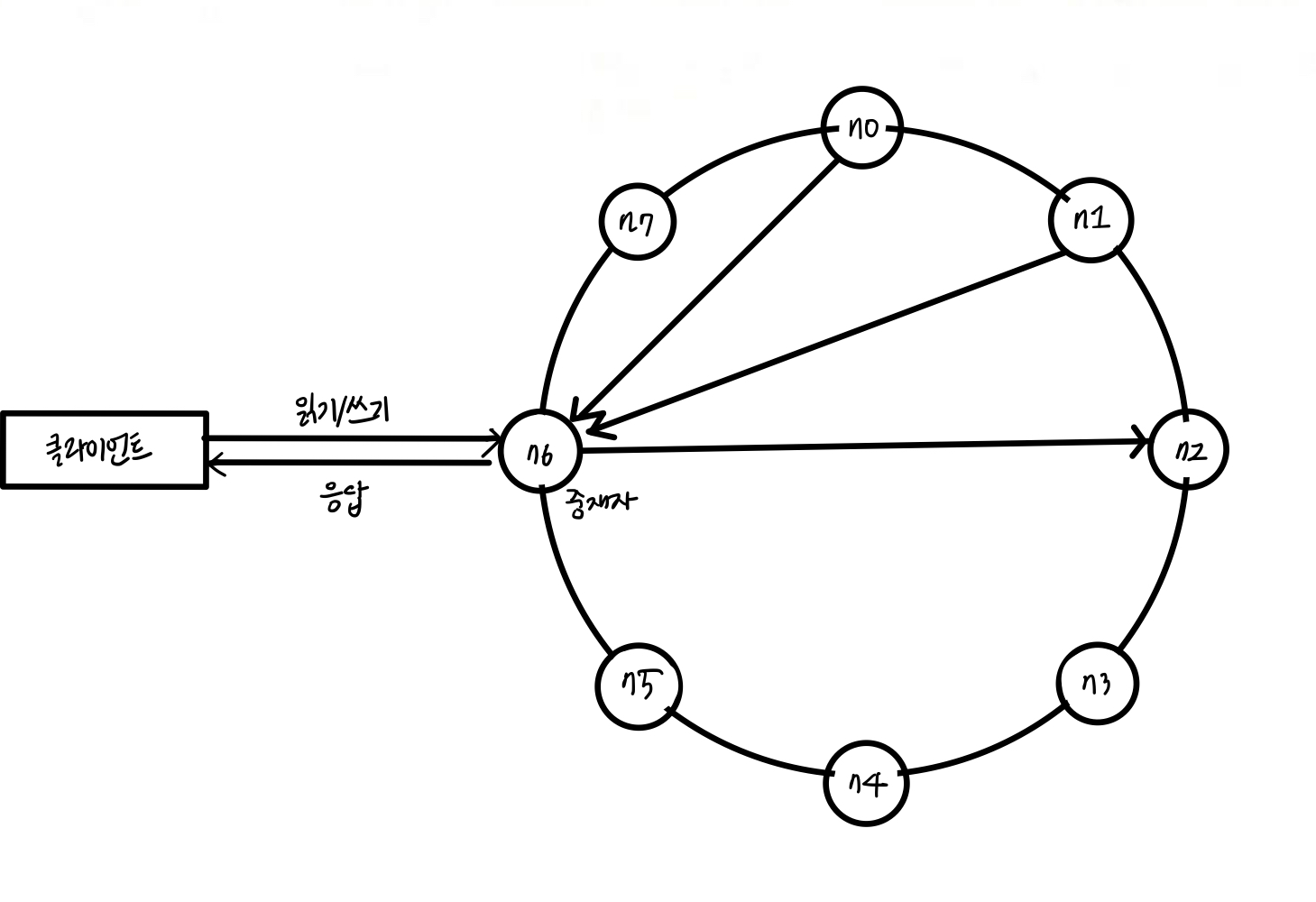
클라이언트는 키-값 저장소가 제공하는 API
get(key)와put(key, value)로 통신한다.중재자는 클라이언트에게 키-값 저장소에 대한 프락시 역할을 하는 노드다.
🤷 중재자 노드가 왜 필요해요?
- 알맞은 노드로 전송: 클라이언트에서 데이터가 존재하는 노드 위치를 미리 알고 전송하기 복잡하기에 대신 연결해준다.
- 노드 추가/삭제 시, 변경된 노드의 위치에 따라 라우팅 처리를 해준다.
- 부하 분산: 특정 노드로 트래픽이 몰리거나, 특정 노드 발생 시 대체 노드로 전송해주는 등 안정적 운영을 가능하게 해준다.몰리지 않게 부하 분산을 해줄 수 있다.
노드는 안정해시의 해시링 위에 분포한다.
데이터는 여러 노드에 다중화한다.
모든 노드가 같은 책임을 지기에 SPOF(Single Point of Failure) 문제를 방지할 수 있다.
🟢 각 노드마다 완전 분산 설계에 맞게, 아래 기능을 모두 지원한다!
- 클라이언트 API
- 장애 감지
- 장애복구 매커니즘
- 데이터 충돌해소
- 다중화
- …
쓰기 경로에서 일어나는 일
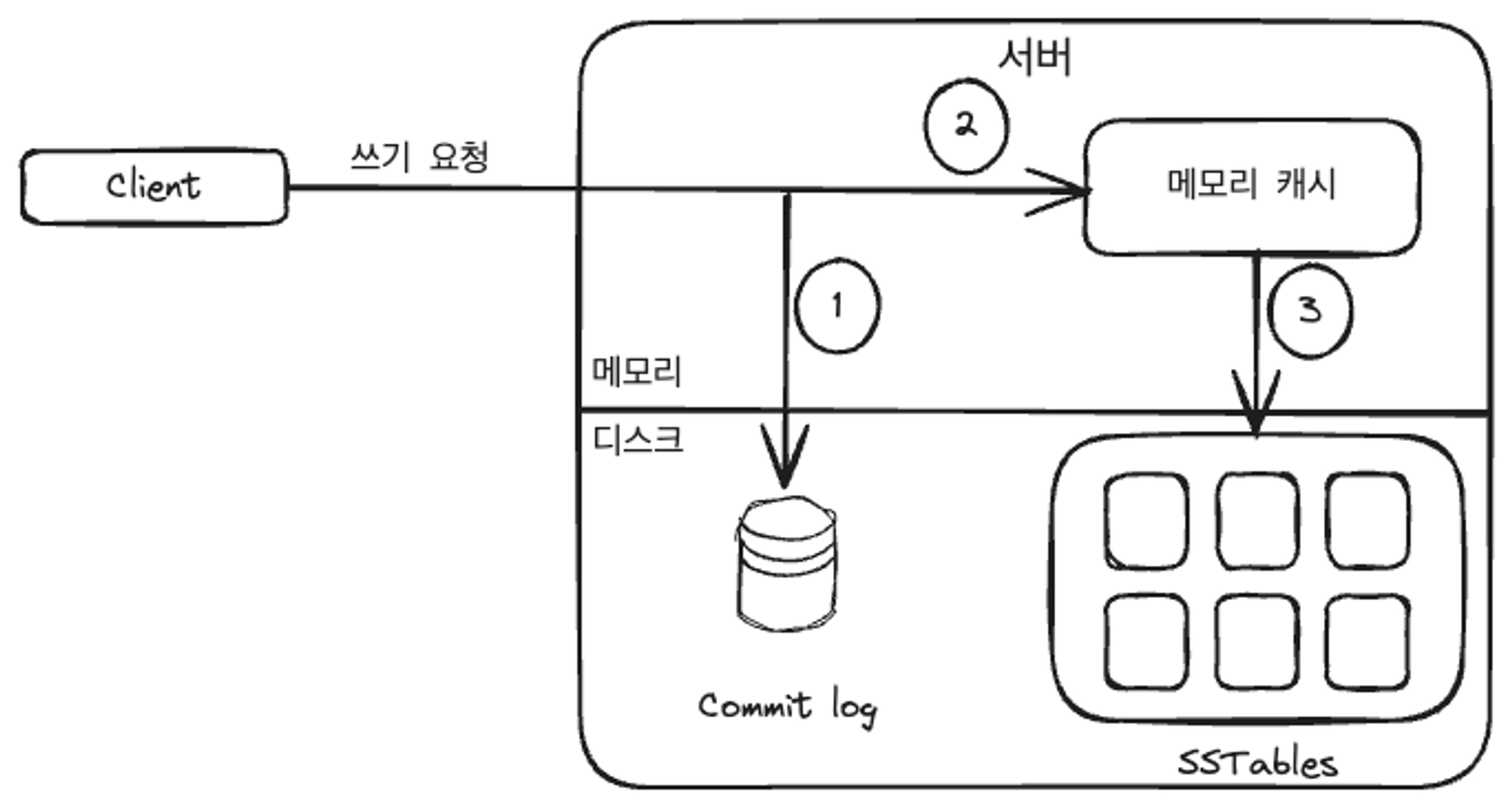
쓰기 요청을 커밋로그 파일에 기록
데이터는 메모리 캐시에 기록 (디스크)
메모리 캐시가 넘치면(가득차거나, 어떠한 임계치 도달), 데이터는 디스트에 있는 SSTable에 기록
SStable: Sorted-String Table의 약어로 키-값의 순서쌍을 정렬된 리스트 형태로 관리하는 테이블
읽기 경로에서 일어나는 일

일단 읽기 요청을 받은 노드는 데이터가 메모리 캐시에 있는지 확인한다. -> 캐시에 있다면 데이터를 반환한다.
없다면 디스크에서 가져온다. 이 때, 블룸 필터를 사용한다.
블룸 필터(Bloom Filter): 데이터가 존재하는지 빠르게 확인하여 디스크 접근을 줄임.
블룸필터를 통해 SSTable에 키가 보관되어 있는지 확인하고, 데이터를 가져와서 클라이언트에 반환한다.
4. 결론 및 요약
키-값 저장소는 단순하지만 강력한 데이터 모델을 제공하며, 높은 성능과 확장성을 갖춘 시스템을 구축하는 데 중요한 역할을 한다.
💡 키-값 저장소를 최적화하는 핵심 포인트
- 데이터 모델 설계: 단순한 Key-Value 매핑을 활용하되, 해시 키와 인덱싱 전략을 최적화.
- 데이터 접근 속도 최적화: 샤딩(Sharding) 전략, 정족수 합의(Quorum) 모델, 그리고 장애 복구 메커니즘
- 일관성과 가용성: CP 또는 AP 중 시스템 요구사항에 맞는 선택.
- 확장성과 장애 대응: 샤딩, 다중화, 장애 복구 기술 적용.
- 성능 최적화: 캐싱, 블룸 필터, SSTable 활용.
실제 서비스에서 키-값 저장소는 캐싱, 세션 관리, 로그 저장, 분산 시스템의 중간 계층 등 다양한 용도로 활용된다.
결국, 키-값 저장소는 단순한 구조 속에서도 효율적인 데이터 분산과 장애 대응을 통해 고성능을 유지하는 것이 핵심이다. 아키텍처 설계 시 각 시스템의 요구사항에 맞는 전략을 선택하는 것이 중요하다.
참고
- 책:
<가상면접 사례로 배우는 대규모 시스템 설계 기초>: 키-값 저장소 설계