⚡OpenAI LLM에 CAG(Cache-Augmented Generation) 적용기: RAG와 무엇이 달랐을까?
지난 포스팅에서 LLM 기반 어플리케이션에서 지식 베이스 활용 방법으로 RAG와 RAG의 대체 방법인 CAG, KAG에 대해 알아본 적이 있습니다.
최근 프로젝트를 진행하며 기존 RAG 방식으로 적용되었으나, Retriver에 소요되는 속도 문제로 인해 이를 개선하고자 CAG를 도입했던 경험을 공유드리겠습니다! 😊
CAG(Cache-Augmented Generation) 컨셉에 대해 더 알고 싶은 분들은 이 포스팅을 참고해주세요!
📌 왜 CAG를 도입하게 되었나?
기존의 RAG(Retrieval-Augmented Generation)는 사용자 질문에 대해 외부 문서를 검색하고 이를 프롬프트에 삽입하는 방식입니다.
이는 매우 유용한 접근이지만, 다음과 같은 단점이 존재합니다.
기존 RAG 방식의 한계
- 응답 지연: 매 요청마다 벡터 검색을 수행 → retriver 평균 0.4초 이상 소요 / API 첫 토큰까지 평균 응답 속도 : 1.43초
CAG가 도움이 될 것이라 생각한 이유
제가 진행하고 있는 프로젝트에서 CAG 방식이 도움이 될 것이라고 생각한 이유입니다.
- Knowledge base의 규모가 작음: 총 3,769 tokens → 프롬프트에 통째로 삽입해도 부담 없음
- 문서 변경 빈도가 낮음: 캐싱 구조에 적합
- RAG에서도 자주 같은 문서가 검색됨: 기존 RAG 방식에서는 6개 문서 중 2개 추출하는 구조였기에, 많은 문서 중 필요한 부분을 부분적 추출의 장점이 약함
💡 OpenAI에서 CAG는 어떻게 작동할까?
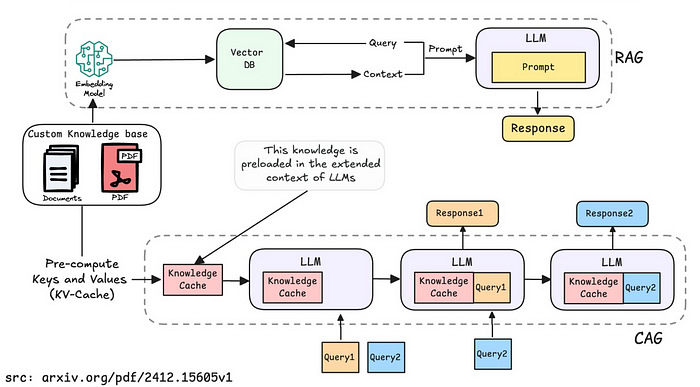 일반적인 RAG 방식과 CAG 방식 비교
일반적인 RAG 방식과 CAG 방식 비교
프롬프트 구성 방식

| 방식 | system prompt | chat history | user prompt |
|---|---|---|---|
| RAG | 페르소나 + 변경정보 1 + 변경정보 2 + Context(RAG 결과물) | 기존 대화 히스토리 | 사용자 질문 |
| CAG | 페르소나 + 전체 Knowledge Base 문서 + 변경정보 1 + 변경정보 2 | 기존 대화 히스토리 | 사용자 질문 |
- System Prompt의 앞 부분을 고정
- OpenAI의 자동 프롬프트 캐싱기능을 이용하기 위해 System Prompt에서 매번 입력 시 마다 변경될 수 있는 정보는 뒤로 정렬하였습니다.
- 프롬프트 캐싱은 토큰의 첫 토큰 1024 token 부터 확인하기 때문에 앞 부분이 최대한 동일하게 해야 프롬프트 캐싱을 최대로 사용할 수 있습니다.
- System Prompt에 전체 Knowledge Base 문서 추가
- 기존 RAG 방식은 Knowledge Base 문서로부터 Retriver 후 Context를 추출하였으나, 그 과정을 제거하기 위해 시스템 프롬프트에 전체 문서를 할당하였습니다.
OpenAI의 Prompt Caching 기능
- 지원 모델: GPT-4o, o1-preview 등
- 작동 원리:
- 최초 요청 시, 첫 1,024 tokens 기준으로 prompt를 캐싱
- 이후 128 token 단위로 확장
- 동일한 prompt에 대해 50% 할인된 비용 적용 (cached token 기준)
전략과 기대 효과
비용 유지
system prompt에 Knowledge Base 문서를 통째로 넣기 때문에 비용 우려가 있으나, 이를 해결하기 위해 문서 앞부분을 고정된 형태로 구성하여 캐싱처리 되도록 함
결과적으로 캐싱 비율을 높여 50% 할인 효과를 극대화하여 토큰수는 증가하여도, 비용은 차이 없도록 함
Retriever 과정 생략으로 API 응답 시간 단축 기대
🔬 실험 결과: RAG vs CAG
응답 속도 & 비용 비교
| 항목 | RAG | CAG |
|---|---|---|
| API 첫 토큰 응답 시간 | 1430 ms | 1019 ms |
| Retriever 소요 시간 | 674 ms | 0 ms |
| LLM 응답 생성 시간 | 712 ms | 809 ms |
| 평균 비용 (OpenAI 기준) | $0.01258 (약 17.7원) | $0.01205 (약 17원) |
- 비용
- 실제 비용 기준으로는 CAG가 RAG와 유사하거나 약간 저렴
- 속도
- CAG가 약 0.4초 빠름 -> API 첫 토큰 응답 시간 1초 감소! (약 40% 빨라짐)
- Retriever 생략이 응답 속도에 긍정적 영향을 줌
CAG 적용이 성공적이었습니다! 짝짝짝! 👏👏👏
🧑💻 코드 구성 방식 비교
RAG 방식
System Prompt.py
1
2
3
4
5
SYSTEM_PROMPT = """
{페르소나}
"""
# 그 뒤 변경 내용 1, 2 조립하여 추가
llm_client.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Chroma DB에서 유사도 검색 실행
vectorstore = self.embedding_service._get_vectorstore()
retriever = vectorstore.as_retriever(
search_kwargs={"k": settings.RETRIEVER_K},
)
retrieved_docs = retriever.invoke(question)
# retriver로 반환된 관련문서를 system prompt에 추가
vars = {
"system_prompt": f"{system_prompt}\n{self._format_retrieved_context(retrieved_docs)}",
"question": question,
"chat_history": format_chat_history(recent_talks)
if recent_talks
else [],
}
messages = self.prompt.format_prompt(**vars).to_messages()
# LLM에 프롬프트 전달 (페르소나 + 변경내용 1 + 변경내용 2 + 검색된 context)
async for chunk in self.model.astream(messages):
if chunk.content:
yield chunk.content
추가로 RAG 방식은 벡터 저장소를 생성하고, 문서를 벡터저장소에 벡터화하여 저장하는 로직이 존재합니다.
CAG 방식
System Prompt.py
1
2
3
4
5
6
7
SYSTEM_PROMPT = """
{페르소나}
{Knowledge Base 문서 전체}
"""
# 그 뒤 변경 내용 1, 2 조립하여 추가
llm_client.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 유사도 검색 및 system prompt에 반환 콘텐츠 추가 로직 없음
vars = {
"system_prompt": system_prompt,
"question": question,
"chat_history": format_chat_history(recent_talks)
if recent_talks
else [],
}
messages = self.prompt.format_prompt(**vars).to_messages()
# LLM에 프롬프트 전달 (페르소나 + KB 전체 + 변경내용 1 + 변경내용 2)
async for chunk in self.model.astream(messages):
if chunk.content:
yield chunk.content
last_chunk = chunk
✅ 결과적으로 CAG는 코드 구조가 단순하고, 속도와 비용 모두에서 경량화된 아키텍처로 작동합니다.
✨ 마무리하며: 언제 CAG를 쓰면 좋을까?
CAG는 다음과 같은 조건에서 강력한 대안이 됩니다.
- 동일한 context를 반복해서 사용하는 상황
- 문서 변경이 드물고, KB(Knowledge Base) 문서의 크기가 작거나 정적일 때
- 실시간 응답 속도가 중요한 UX를 구성할 때
반면, 대화 맥락이 유동적이거나 문서가 자주 바뀌는 경우에는 여전히 RAG가 적합할 수 있습니다.
저는 CAG 방식을 활용하기 위해서는 뭔가 특별한 구현이 더 필요할 줄 알았는데 OpenAI에서 제공하는 Auto Prompt Caching 기능을 활용하면 프롬프트 구조만 잘 짜면 되는 거였네요 ㅎㅎ
이번 기회를 통해 Prompt Caching과 비교성능 테스를 해보아서 즐거운 경험이었습니다!