KAG(Knowledge Augmented Generation): LLM과 지식그래프의 강력한 조합!
지난 번 RAG의 한계를 극복하기 위해 떠오르는 대안인 CAG와 KAG 소개 및 비교 글을 올렸었습니다!
그 후에 KAG에 대해 더 궁금해져서 조금 더 깊어 알아보았습니다 🤗
1. 기존 RAG의 한계
지금까지 우리는 LLM에 학습되지 않은 데이터에 대한 정보를 주입하기 위해 RAG를 많이 사용했었습니다.
하지만 RAG는 몇 가지 치명적 한계가 있었습니다.
1) 논리적 한계
- RAG 시스템은 텍스트 혹은 벡터 유사도 검색에 의존하여 유사한 데이터를 반환합니다. 그러나 논리적 관계에 대한 이해(인과관계, 시간적 종속성, 수치연산)가 없기에, 정확한 답을 얻기 어렵습니다.
- 법이나 과학같은 복잡한 도메인의 경우 여러 정보의 추론 능력이 부족합니다.
2) 중복되거나 불필요한 결과
- 유사도 기반 검색 프로세스는 청크 내에 중복되거나, 불필요한 정보까지도 반환해줍니다. 이로 이해 후속작업에서 의미있는 관점을 추출하기 더 어려워질 수 있습니다.
3) 도메인 특화의 어려움
- 의료나 금융 같은 분야는 매우 정확하고 논리적으로 구조화된 응답이 필요합니다. RAG는 유사도 기반이기에 비슷하고 연관성있는 정보를 제공하지만, 정확한 정보를 준다고 보기는 어렵습니다.
2. KAG란?
KAG(Knowledge Augmented Generation)는 지식 그래프(KG)와 벡터 검색의 장점을 결합하여 대형 언어 모델(LLM)과 상호 보완적으로 작동하는 프레임워크입니다.
이는 RAG(Retrieval-Augmented Generation)의 한계를 극복하며, 더욱 강력한 AI 추론을 가능하게 합니다. 앞서 살펴본바와 같이 RAG는 텍스트 유사도 기반 검색을 활용하여 답변을 생성하지만, 이는 논리적 지식 관계를 고려하지 않아 검색 결과의 정확성이 낮을 수 있습니다.
반면, KAG는 지식 그래프를 활용하여 의미적 정렬(semantic alignment)을 수행하고, 보다 정교한 지식 검색과 추론을 지원합니다.
즉, **KAG는 지식 그래프 + LLM 결합 => 의미적 추론 강화!** 하는 컨셉을 가지고 있습니다.
3. KAG의 주요 특징
1) LLM 친화적인 지식 표현 (LLM-Friendly Knowledge Representation)
KAG는 LLM과 호환되는 지식 표현 시스템(LLMFriSPG) 프레임워크를 사용하여, 모델이 데이터를 더 쉽게 이해하고 활용할 수 있도록 돕습니다.
LLMFriSPG의 작동 방식은 뒤에 더 자세히 설명하겠습니다.
LLMFriSPG?
- LLM: Large Language Model
- Fir: Friendly
- SPG: Semantic Property Graph, 의미와 속성을 가진 그래프 구조, 데이터 간의 관계를 의미 있게 표현하는 그래프 기반 데이터 구조
2) 상호 색인(Mutual Indexing)
지식 그래프와 원본 텍스트를 상호 연결하는 색인 방식으로, 검색된 정보를 보다 효과적으로 조직화할 수 있습니다.
즉, 구조화된 지식과 비구조화된 텍스트를 연결하여 정보를 더 쉽게 찾고 정리하는 데 도움을 줍니다.
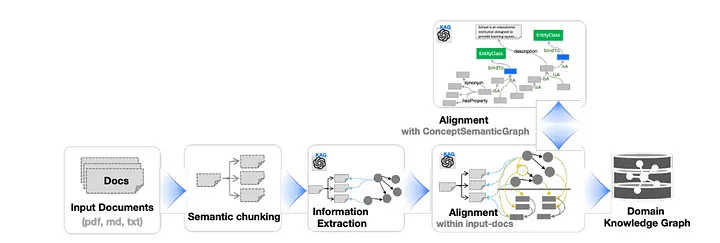
3) 논리적 형식 기반 하이브리드 추론 엔진 (Logical-Form-Guided Hybrid Reasoning Engine)
KAG는 계획, 검색, 수학적 연산을 조합하여 자연어 질문을 구조화된 문제 해결 단계로 변환합니다.
이를 통해서 KAG가 자연어 질문을 구조화된 단계로 전환하여 복잡한 질문을 더 잘 처리할 수 있습니다.
4) 의미적 추론을 통한 지식 정렬 (Knowledge Alignment with Semantic Reasoning)
KAG는 의미적 추론을 사용하여 지식을 사용자의 질문과 연결시킵니다. 정보가 맥락에 맞고, 사용자의 요구에 부합하도록 하여 답변의 정확성을 향상시킵니다.
5) 향상된 자연어 처리 (Improved Natural Language Processing)
질문을 이해하고, 논리적으로 사고하며, 명확한 답변을 생성하는 성능이 개선됩니다.
4. LLMFriSPG 개념 및 데이터 흐름
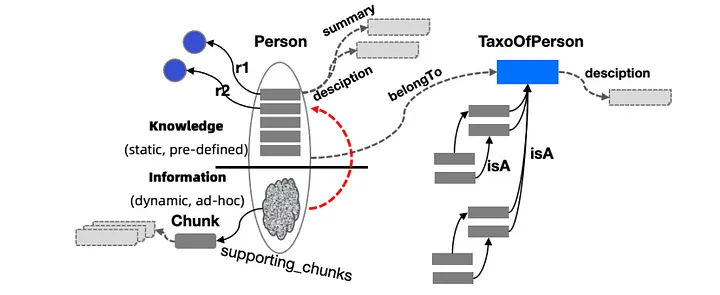
LLMFriSPG는 구조화된 지식(Knowledge)과 비구조적 정보(Information)를 결합하여 LLM이 이해할 수 있는 방식으로 변환하는 기술입니다.
심층적인 텍스트-컨텍스트 인식, 동적 속성, 지식 계층화를 통해 LLM이 지식을 더 효과적으로 활용할 수 있도록 설계되었습니다.
주요 개념은 다음과 같습니다.
- Person 노드: 주요 개체로,
r1,r2등의 관계를 통해 다른 개체와 연결됩니다. Knowledge vs. Information
- Knowledge
- 정적인 데이터로 미리 학습된 데이터
- 구조화된 데이터로, 지식 그래프(Knowledge Graph)로 표현
- Information
- 동적인 데이터로 ad-hoc 방식으로 생성
- 구조화되지 않은 문서, 청크 등이 포함됨
- Knowledge
Chunk (정보 조각)
- 비정형 데이터를 작은 단위로 나누어 저장하며, KAG의 검색 및 추론에 사용됩니다.
- LLM이 이해하고 처리할 수 있도록 변환되며,
supporting_chunks로 표현됨
TaxoOfPerson (개인 분류 체계)
- “Person” 개체(노드)가 속할 수 있는 계층적 분류 구조
belongTo관계를 통해 Person과 연결됩니다.isA관계를 사용하여 계층적 관계를 형성합니다.- 예를 들어, “Student”가 “Person”의 하위 개념일 수 있습니다.
1) 데이터 처리 과정
- 비정형 정보(Chunk) 수집
- 문서, 웹페이지, 이미지 등에서 정보를 추출하여 Chunk 형태로 저장합니다.
- 지식과 정보의 분리 및 색인
- 정적인 지식(Knowledge)과 동적인 정보(Information)를 분리하여 관리합니다.
- Knowledge는 Knowledge Graph 형태로 저장됩니다.
- Information은 개별 supporting_chunks로 저장됩니다.
- 상호 연결 (Mutual Indexing & Relation Mapping)
- Person과 관련된 정보를
description필드를 통해 연결합니다. - 지식 그래프 내에서 의미적 유사성을 기반으로
r1,r2등의 관계를 매핑합니다.
- Person과 관련된 정보를
- 지식 정렬 및 추론 (Semantic Alignment & Reasoning)
- LLM이 질문을 이해하고 적절한 응답을 생성할 수 있도록 의미론적 정렬을 수행합니다.
- Knowledge Graph를 기반으로 의미적 관계를 파악하고, Information에서 추가 데이터를 가져와 응답을 보강합니다.
- Taxonomy(분류 체계) 적용
- 개체를 “TaxoOfPerson”과 같은 분류 체계에 정렬하여 의미적으로 구조화된 데이터로 변환합니다.
- 이 과정에서
isA및belongTo관계가 활용됩니다.
2) LLM과의 통합 방식
- LLM이 질문을 받으면, Knowledge Graph를 탐색하여
Person과 관련된 정보를 검색합니다. - 정보가 부족한 경우,
supporting_chunks에서 추가 데이터를 찾아보거나, 새로운 정보를 동적으로 생성할 수도 있습니다. - TaxoOfPerson을 활용하여 “이 개체가 속하는 범주”를 파악하여 질문에 맞는 정교한 답변을 제공합니다.
5. KAG의 동작 흐름
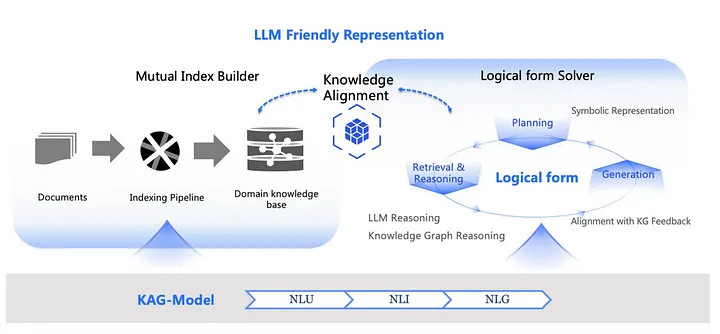
1) KAG의 세 가지 핵심 구성 요소
KAG 아키텍처는 세 가지 주요 구성 요소로 이루어져 있습니다.
- KAG-Builder:
- 오프라인 색인을 구축하는 역할을 합니다.
- LLM과 호환되는 지식 표현 프레임워크를 제안하고, 지식 구조와 텍스트 조각 간의 상호 인덱싱 메커니즘을 구현합니다.
- KAG-Solver:
- 논리적 형식(Logical Form) 기반의 하이브리드 추론 엔진을 사용합니다.
- LLM 추론, 지식 그래프 추론, 수학적 논리 추론을 통합하여 의미적 정렬을 수행합니다.
- KAG-Model:
- 일반적인 언어 모델을 기반으로 하며, 각 모듈에서 필요한 기능을 최적화하여 전체적인 성능을 향상시킵니다.
2) 동작 과정
- Mutual Index Builder
- 문서(Document)에서 정보를 추출하여 인덱싱 파이프라인(Indexing Pipeline)을 거쳐 도메인 지식 베이스(Domain Knowledge Base)에 저장합니다.
- Knowledge Alignment (지식 정렬)
- 저장된 데이터는 LLM 친화적인 방식으로 정렬되며, 의미적으로 관계를 맺습니다.
- Logical Form Solver (논리적 형식 해석기)
- 질문을 입력하면, 기호적 표현(Symbolic Representation)으로 변환됩니다.
- 검색 및 추론 단계를 거쳐 의미적 정렬을 수행하고, 지식 그래프 기반으로 최적의 응답을 생성합니다.
- 생성된 응답은 KG 피드백과 정렬됩니다.
- 최종 응답 생성 (Generation)
- 정렬된 데이터를 바탕으로 응답을 생성하며, 의미적 일관성을 유지하기 위해 KG 데이터를 활용합니다.
마무리
KAG는 지식 기반을 이용하여 LLM을 사용하는 방식으로 기존 RAG의 한계를 많이 보완해줄 수 있는 시스템으로 보입니다.
그런데 아직 제게 개념들이나 흐름이 너무 어렵네요 ㅠㅠ
혹시 직접 구현을 테스트해보고 싶으신 분들은 OpenSPG의 github과 구현과정을 stepbystep으로 설명해둔 medium 글을 참고해보시면 될 것 같습니다!
저는 우선 Knowledge Graph를 활용한 RAG 방식에 대해 공부해보고, 직접 코드로 적용해본 후에 KAG를 실습해볼 예정입니다 :)
참고