조회 성능을 극대화하는 CQRS 아키텍처, 사례 중심!
다양한 테이블의 다양한 정보 구성을 한 번에 조회해야 하는 경우가 있습니다. 그런 경우 테이블을 조인조인해서 들어가서 쿼리의 성능이 떨어지거나, 어플리케이션 내에서 여러 번의 반복을 수행해야 하는 등 응답 속도가 상당히 지연되어 사용자에게 불편을 초래할 수 있습니다.
이런 경우 고려해볼 수 있는 패턴이 바로 CQRS 패턴입니다!
CQRS 패턴은 명령과 조회의 책임을 분리한다.는 컨셉을 가지고 있습니다.
“Command and Query Responsibility Segregation”
각 단어의 의미에 대해 알아봅시다!
Command(명령): 데이터의 상태를 변경하는 작업입니다. 데이터 생성, 수정, 삭제와 같은 작업이 포함됩니다.
- Command는 시스템의 상태를 변경하는 책임이 있습니다.
- 보통 비동기 방식으로 처리되어 데이터베이스에 기록됩니다.
Query(조회): 데이터를 조회하는 작업입니다. 데이터베이스에 저장된 정보를 읽고 클라이언트에게 반환합니다.
- Query는 시스템의 상태를 변경하지 않습니다.
- 보통 동기 방식으로 처리되어 빠른 응답을 목표로 합니다.
책임 분리:
- Command Model (명령모델): 쓰기 작업을 처리하는 모델로, 데이터베이스 변경에 초점을 맞춥니다. 이 모델은 비즈니스 로직과 데이터 유효성 검사를 포함할 수 있습니다.
- Query Model (조회모델): 읽기 작업을 처리하는 모델로, 클라이언트의 요청에 최적화된 방식으로 데이터를 반환합니다. 읽기 성능을 높이기 위해 복잡한 조인 없이 설계되거나 캐싱을 활용할 수 있습니다.
저는 우아콘2021에서 발표한 B마트 전시 도메인 CQRS 적용하기 영상을 통해 적용된 사례 중심으로 CQRS 패턴에 대해 알아보았습니다.
컨셉
적용 전 보통의 아키텍쳐
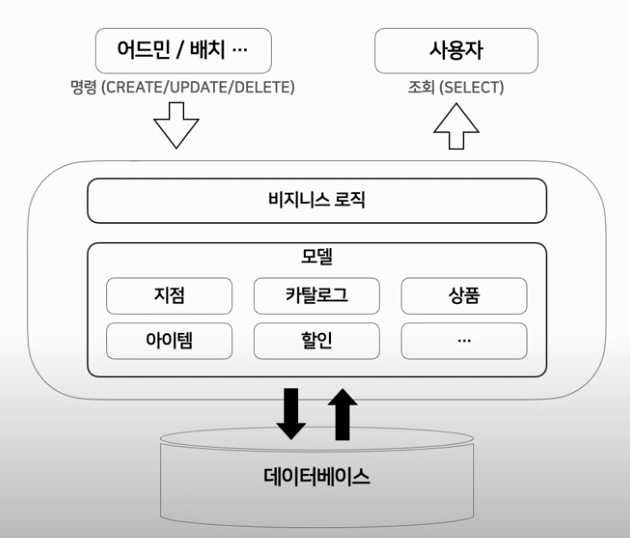
보통의 아키텍쳐는 명령(CREATE/UPDATE/DELETE)와 조회(SELECT)에 대해 같은 모델을 사용하고, 같은 DB에 작업을 하는 경우가 일반적입니다.
그런데 요구사항이 복잡해지며 모델이 복잡해지고, 그러다보면 조회 시에 사용하지 않는 정보들까지도 모델에서 관리하고 있는 구조가 될 수 있습니다.
그런 경우 명령과 조회 로직이 서로 하나의 공통된 모델을 바라보는 경우, 영향도와 의존성을 갖게 될 수 밖에 없습니다. 조회 시에 의도치 않은 데이터를 사용하게 되거나, 리팩토링이 까다로워지는 등의 문제가 발생하게 되는 것이죠.
CQRS 패턴 적용 아키텍쳐
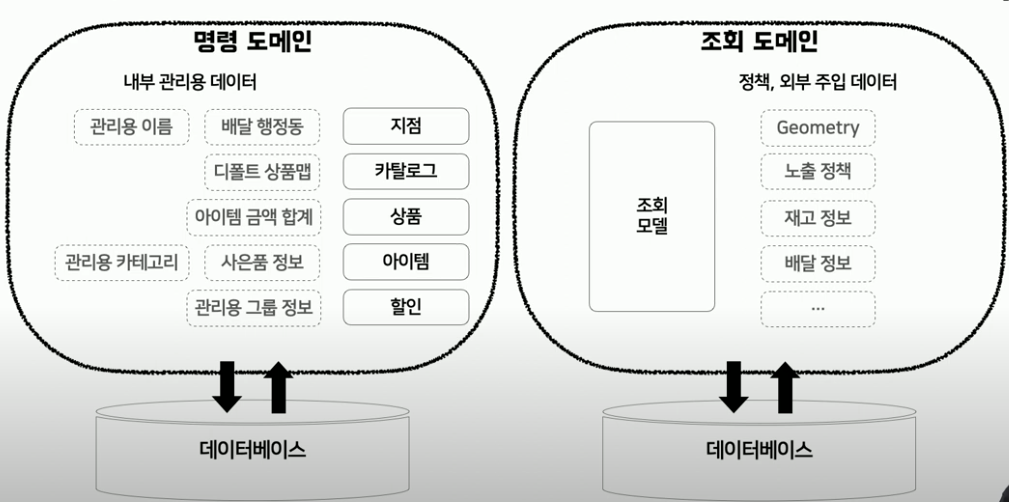
명령 도메인과 조회 도메인을 분리하는 것이 CQRS 패턴의 목표입니다.
적용 방법
1. 모델 분리
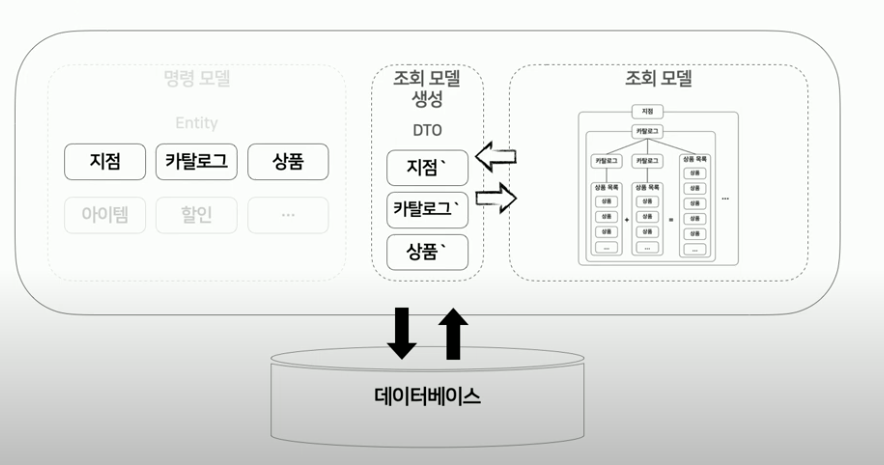
먼저 복잡하게 합쳐진 모델을 각 각 목적에 맞게 분리합니다.
명령 모델은 기존 모델을 그대로 사용하고, 조회 모델에서는 조회에서만 사용되는 데이터를 정의해서 다시 정의합니다.
보통 조회모델은 엔티티 전체가 아닌 일부 데이터이기 때문에 DTO를 이용하여 조회 모델을 생성하는 것을 권장합니다.
조회 모델을 정의할 때는 정규화된 테이블 구조는 비정규화하는 작업이기 때문에, 성능 문제가 발생할 가능성이 있습니다. 이를 위해 중간에 캐시를 추가하여 성능 문제를 해결할 수 있지만 힙메모리가 늘어나 결국 성능을 저하하게 될 수 있는 위험이 있습니다.
2. 조회모델의 생성/저장과 조회 시점 분리
조회모델에서 조회모델 생성/저장 호출
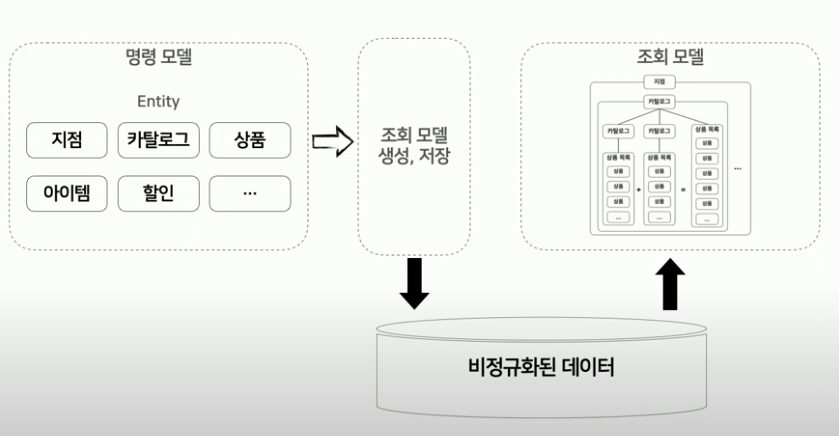
조회모델 생성/저장과 조회모델 조회 시점의 기능 분리
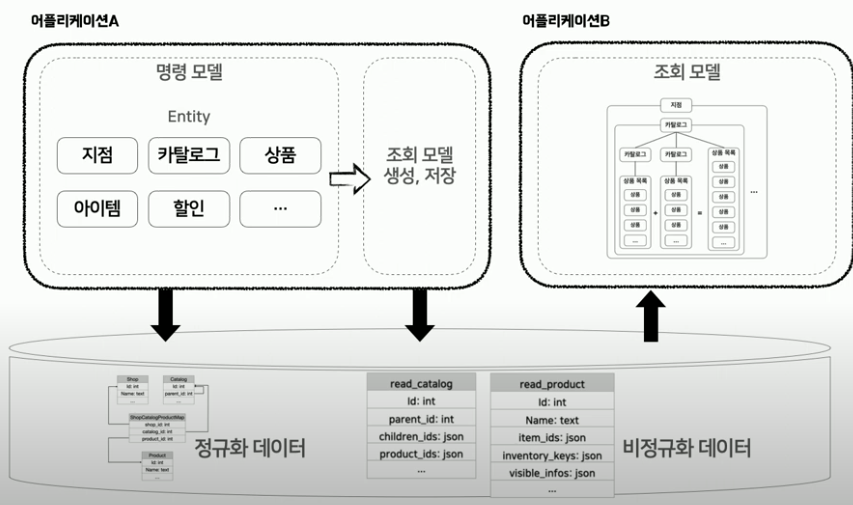
기존에는 조회모델이 조회모델 생성/저장을 호출하는 구조였지만, 어플리케이션 단위로 조회모델의 생성/저장되는 시점과 조회모델을 조회하는 시점을 분리할 수 있습니다.
명령 로직 수행 시에 조회 모델을 생성, 저장하는 것입니다. 이 때, 조회 시에 사용되는 비정규화된 데이터 그대로의 모습으로 저장합니다.
CQRS 패턴 사용 시에는 조회모델이 DB를 조회할 때 JOIN 혹은 기타 연산 작업을 극도로 제한하는 걸 권장합니다. 그렇기 때문에 조회를 위한 새로운 형식-비정규화된 데이터 형식-으로 조회모델을 재정의 해야 합니다. 비정규화된 데이터 모습이기 때문에 JSON으로 많이 사용하며, RDBMS가 아닌 nosql 등을 많이 사용하게 됩니다.
read_* 구조로 바로 조회 가능한 구조로 조회모델을 정의해줄 수 있습니다.
명령 수행 시점에 조회 모델의 필요한 데이터를 생성/저장하고, 조회 모델을 읽어오는 시점에서는 이미 만들어진 최종 결과물을 조회만 하면 되어 안정적입니다. (명령과 조회의 컨텍스트 완전 분리)
3. 성능 높이기
데이터 정합성 관리
write model과 read model의 데이터 분리하였기 떄문에, 저장소가 분리되게 됩니다. 이렇게 서로 다른 저장소를 가지게 되면 각 각 용도에 맞는 db vendor를 적용할 수 있습니다. 조회 성능의 경우 최적화를 위해 RDB가 아닌 redis, nosql을 사용하여 쿼리 성능을 높일 수 있습니다. 하지만 이렇게 저장소가 분리되면 두 저장소 간 정합성 유지를 위해 모니터링 등을 통한 안정화 과정이 필요하기에 유의해야 합니다.
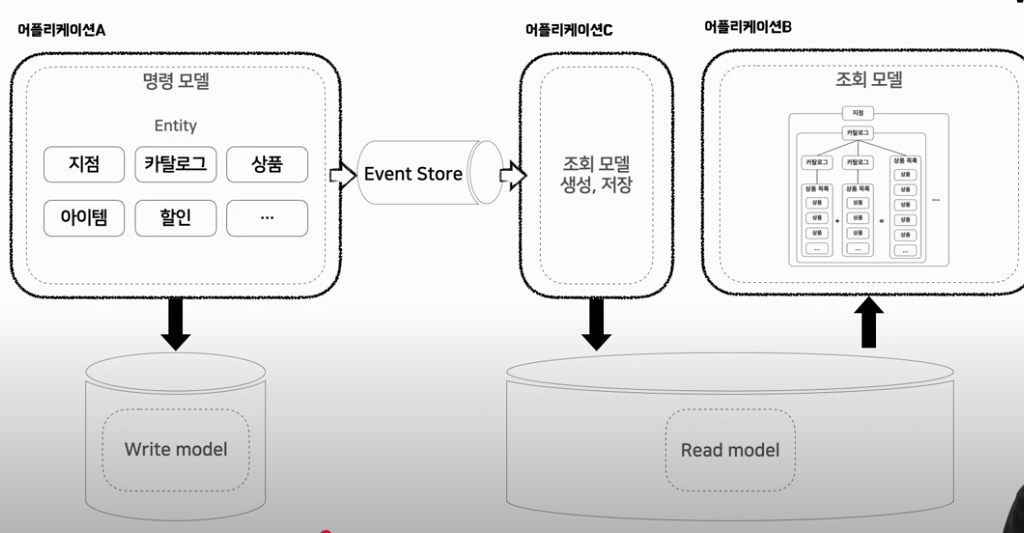
조회 모델 생성/저장 어플리케이션 분리
조회 시에는 비정규화된 데이터를 바로 조회만 하면 되어 매우 이득이지만, 명령 시에는 갑자기 비정규화된 조회 모델을 생성,저장해야하는 부담이 늘어나게 됩니다.
이를 해결하기 위해 명령 로직 수행 후 조회모델 저장/생성 부분을 Event Sourcing 하여 처리합니다.
명령 로직에서 수행 뒤, 조회모델 생성/저장이 필요한 경우 이 내용을 Event Store에 전달해둡니다. 그럼 명령 로직 어플리케이션은 부담이 없어집니다. 조회모델 생성/저장하는 로직은 Event Store를 consume하고 있다가, 이벤트가 발생하면 수행합니다.
이렇게 어플리케이션을 분리하면 명령 로직 어플리케이션에서의 부담을 줄일 수 있습니다.
즉 A 어플리케이션에서는 명령 로직 수행, B 어플리케이션에서는 이벤트 발생 시, 조회모델 생성/저장, C 어플리케이션에서는 조회 api 요청 시 조회모델의 응답값 반환만 수행하도록 업무를 분담해줍니다.
CQRS는 언제 적용하면 좋을까?
- 조회가 많고, 명령 로직이 적은 어플리케이션의 특정을 가진 경우 큰 이점을 가집니다.
- UX와 비즈니스 요구사항이 복잡해져서 모델이 점점 복잡해져 명령과 조회의 영향도가 너무 커질 때
- 조회의 성능을 크게 향상 시키고 싶을 때
- 명령-데이터 관리 영역 / 조회-뷰로 전달하는 영역의 책임 분산 필요 시
CQRS 적용 시 유의점
- 복잡성 증가 : 어플리케이션의 구조가 복잡해지고, 데이터 동기화 구현 등의 아키텍쳐가 복잡해집니다
- 일관성 문제: 저장소를 분리하기 때문에 설계에 주의와 안정화가 필요합니다
- 학습 곡선 : CQRS와 이벤트 소싱에 대한 지식이 없는 경우 학습이 필요합니다.