RAG의 대안! CAG(Cache-Augmented Generation)와 KAG(Knowledge Augmented Generation) 비교
AI 모델이 최신 정보를 바탕으로 정확한 답변을 제공하려면 다양한 기술이 필요하다.
기존에는 RAG(Retrieval-Augmented Generation) 이 가장 널리 사용되었지만, 최근에는 CAG(Cache-Augmented Generation) 및 KAG(Knowledge Augmented Generation) 같은 새로운 방법들이 등장하며 RAG의 한계를 극복하고 있다.
CAG와 KAG 모두 RAG의 한계를 보완하기 위한 기술이지만, 작동 방식의 초점에서 차이가 있다.
두 기법에 대해 알아보자!
1. CAG(Cache-Augmented Generation)의 핵심 개념
CAG는 LLM의 확장된 컨텍스트 메모리를 활용하여 사전 로드된 지식을 캐시(Cache)로 저장하고 이를 추론 시 활용하는 방식이다. 즉, 필요한 정보를 미리 LLM의 컨텍스트에 넣어둠으로써, 매번 지식을 검색하는 RAG 방식의 비효율성을 제거하는 것을 목표로 한다.
✅ CAG의 동작 방식
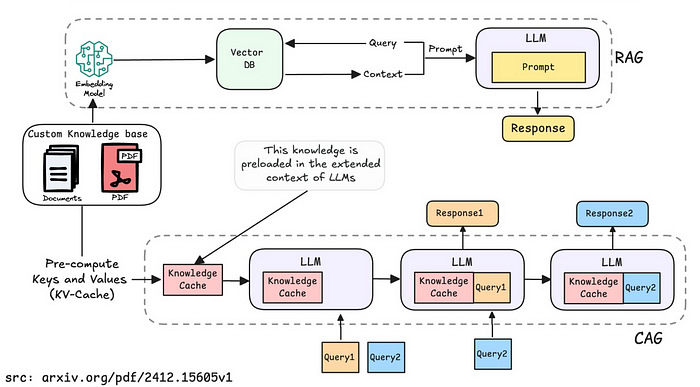
- 사전 로드(Preloading External Knowledge)
- 사용자가 자주 사용할 문서를 키-값(KV) 캐시 형태로 변환하여 저장한다.
- 저장된 KV 캐시는 추후 동일한 질문이 들어왔을 때 재사용할 수 있다.
- 추론(Inference)
- 질의가 들어오면 사전 로드된 KV 캐시를 참조하여 즉각적인 응답을 생성한다.
- RAG처럼 외부 데이터베이스에서 검색할 필요가 없으므로 지연 시간(latency)이 거의 없음.
- 캐시 리셋(Cache Reset)
- 새로운 문서가 추가될 경우, 기존 캐시를 지우고 다시 로드해야 한다. (캐시 업데이트)
- 그렇기 때문에 자주 변경되는 데이터에는 적합하지 않음.
🔹 CAG의 장점
✔ 즉각적인 응답 → 기존 RAG는 외부 지식 검색에 시간이 걸리지만, CAG는 미리 저장된 지식을 사용하여 즉시 응답 가능 (대용량 데이터 처리 시 최대 40.5배 빠름)
✔ 낮은 운영 비용 → 검색 시스템(예: 벡터 DB)과 같은 별도의 검색 인프라가 필요 없고, 지식이 미리 로드되므로 검색 관련 오베헤드 감소
✔ 응답 정확도 향상 → 사전 로드된 문서들이 LLM의 컨텍스트에 통합되므로, 보다 일관되고 연결된 응답 제
✔ 일관된 문맥 유지 → RAG가 문서 검색 시 문맥이 분절되는 문제를 해결 (청크 단위에 따라 문맥이 잘릴 수 있음)
🔹 CAG의 단점
✖ 실시간 데이터 반영 어려움 → RAG처럼 즉시 새로운 문서를 검색해 반영할 수 없으며, 미리 로드된 데이터만 사용할 수 있음
✖ 캐시 업데이트 문제 → 모델 실행 전에 정보를 미리 저장해야 하므로, 실시간 업데이트가 어렵다
✖ 메모리 사용량 증가 → LLM의 컨텍스트 내에 모든 데이터를 저장해야 하므로, 대용량 데이터 처리 시 메모리 부담 증가
2. KAG(Knowledge Augmented Generation)의 핵심 개념
KAG는 지식 그래프(Knowledge Graph, KG)와 LLM을 결합하여 의미적 추론(Semantic Reasoning)을 강화하는 방식이다. 단순 검색(RAG)이나 사전 로드(CAG) 방식이 아닌, 지식 간의 관계를 이해하고 추론하는 것이 목표이다.
✅ KAG의 동작 방식
지식 관리(Knowledge Management)
- 문서(PDF, 차트, 테이블 등)를 업로드하여 구조화된 지식 그래프(Knowledge Graph, KG)를 생성
- 단순히 문서를 저장하는 것이 아니라, 각 정보 간의 관계를 그래프 구조로 변환
- 문서 내 정보들을 지식 노드(Entities)와 관계(Edges)로 변환하여 저장
하이브리드 추론(Hybrid Reasoning)
의미적 추론(Semantic Reasoning), 논리적 추론(Logical Reasoning), 수리적 추론(Mathematical Reasoning) 등을 조합
단순 검색(RAG)이나 사전 로드(CAG) 방식과 달리, 지식 간의 관계를 바탕으로 다중 홉(Multi-Hop) 질의 처리 가능
📒다중 홉 검색
- 하나의 문서에서 정답을 찾을 수 없는 경우, 여러 개의 문서를 연속적으로 검색하여 정보를 연결한 후 최종적인 답변을 생성하는 검색 방식
질의 응답(Question Answering)
- 사용자의 질문을 분석하여 지식 그래프에서 관련된 정보와 관계를 탐색
- 단순히 문서를 검색하는 것이 아니라, 논리적으로 연결된 정보를 바탕으로 응답 생성
🔹 KAG의 장점
✔ 멀티 홉 추론 가능 → 여러 문서를 조합하여 응답할 수 있으며, 지식 간의 연결성을 활용하여 복잡한 질문 처리 가능
✔ 구조화된 지식 활용 → 숫자, 시간 관계, 전문가 규칙 등 RAG/CAG가 이해하기 어려운 논리적 데이터를 다룰 수 있음
✔ 지속적인 지식 확장 가능 → 새로운 지식을 추가하면 전체 시스템을 다시 훈련할 필요 없음
🔹 KAG의 단점
✖ 구축이 복잡함 → 지식 그래프를 생성하고 이를 모델과 연동하는 과정이 필요
✖ 실시간 응답 속도가 느릴 가능성 있음 → 지식 그래프 탐색이 추가되므로 검색 속도가 느려질 수 있음
✖ 운영 비용 증가 → RAG나 CAG보다 복잡한 인프라 구축이 필요하며, 그로 인한 유지 비용이 클 수 있음
3. CAG vs. KAG 비교
| 항목 | CAG(Cache-Augmented Generation) | KAG(Knowledge Augmented Generation) |
|---|---|---|
| 핵심 개념 | LLM의 확장된 컨텍스트를 활용하여 사전 로드된 지식을 캐시로 저장하고 활용 | 지식 그래프를 기반으로 논리적 추론 및 다중 홉 검색 수행 |
| 지식 처리 방식 | 키-값(KV) 캐시를 사전 로드하여 빠르게 참조 | 지식 그래프(KG)를 생성하고 관계를 기반으로 추론 |
| 검색 방식 | 검색 없이 사전 로드(캐시)된 지식 사용 | 지식 그래프 기반 의미적 검색 + LLM 논리적 추론 수행 |
| 응답 속도 | 매우 빠름 (미리 로드된 데이터 활용) | 상대적으로 느림 (지식 그래프 탐색 및 논리적 추론 필요) |
| 정확도 | 정확도 향상 (일관된 문맥 유지) | 더 높은 정확도 (다중 홉 질의 가능) |
| 실시간 정보 업데이트 | 어렵다 (캐시 업데이트 필요) | 가능 (새로운 지식 그래프 추가 가능) |
| 구축 난이도 | 비교적 쉬움 (KV 캐시 구축) | 어려움 (지식 그래프 구축 필요) |
| 활용 사례 | 빠른 응답이 필요한 챗봇, 고객 지원, FAQ 시스템 | 연구, 법률, 금융 분석 등 논리적 추론이 필요한 영역 |
4. 결론: 언제 CAG vs. KAG를 사용할까?
✔ 빠른 질의 응답(Q&A) 시스템이 필요하다면? → CAG
✔ 지식 기반 논리적 추론이 필요하다면? → KAG
✔ 대규모 데이터셋, 실시간 업데이트가 필요하다면? → KAG
CAG는 RAG의 단점을 극복하는 대안이지만, KAG는 CAG보다 더 강력한 논리적 추론을 제공할 수 있다.
결국, 사용자의 목표와 데이터 특성에 따라 CAG와 KAG 중 적절한 방법을 선택해야 한다.
➕CAG vs. RAG 벤치마크 실험 결과
최근 HotpotQA 데이터셋을 사용한 벤치마크 실험에서 CAG와 RAG를 비교한 결과, CAG가 작은 데이터셋에서는 효과적이지만, 대규모 데이터에서는 한계가 있음이 확인되었다.
📊 실험 조건
- 모델: Meta-Llama 3.1 8B Instruct
- 질문 수: 50개
- 데이터 크기: 50개 문서 vs. 500개 문서
- 측정 지표: BERT-Score (정답과의 의미적 유사도)
📊 실험 결과
| 방법 | 작은 데이터셋(50문서) | 큰 데이터셋(500문서) |
|---|---|---|
| CAG | 높은 정확도 (즉시 응답) | 성능 저하 (문서 크기 초과) |
| RAG | 속도는 느림 | 정확도 유지 (검색 최적화 가능) |
📊 핵심 분석
- CAG는 작은 데이터셋에서는 빠르고 효과적이지만, 문서 크기가 커지면 컨텍스트 제한에 걸려 성능이 급격히 저하됨
- RAG는 검색 속도가 느리지만, 문서 크기가 커져도 최적화된 검색을 통해 정확도를 유지함
이 실험 결과는 KAG에도 적용될 수 있다.
- KAG는 RAG처럼 검색을 활용하면서도, 의미적 관계를 추가하여 더 높은 정확도를 제공할 수 있음
- 즉, RAG보다 정확하고, CAG보다 확장성이 뛰어난 대안이 될 수 있음
참고