[Deep Learning Basic] 05_Pytorch를 활용한 데이터 분석 실습
[Deep Learning Basic] 05_Pytorch를 활용한 데이터 분석 실습
진행 순서
- 데이터 읽어오기
데이터 전처리
- 데이터프레임과 시리즈로 구분
Pandas 라이브러리의 기본 데이터 구조
- 데이터프레임: 2차원 테이블 (여러개의 시리즈의 결합)
- => 독립 변수값(입력 특성)
- 시리즈: 1차원 레이블(인덱스) => 하나의 컬럼
- => 종속 변수값(예측 대상)
- train과 test 데이터 나누기
- 스케일링 진행
- 데이터의 크기가 편차가 클 때 오차를 줄이기 위해 스케일링 진행
- torch tensor로 변환
선형회귀 모형 생성
- 모델 class 정의
- model instance 생성
- 손실함수/optimizer 정의
- Dataset Loader 생성
Train set으로 훈련 수행
- Batch data Load
- model 을 이용하여 batch data 예측
- loss value 계산
- optimizer 에 저장된 grad value clear
- loss value backpropagate
- optimizer update
Test set으로 모델 평가
- criterion 으로 손실값 확인
- Loss 시각화
- Test set으로 예측
평가
- MSE, R2 계산
- True vs. Predicted 시각화
데이터 구분 종류
- train data: 모델 학습용 데이터
- valid data: 학습된 모델이 예측한 값과 비교하기 위한 실제 데이터
test data
- 훈련과정에서 valid data를 직접 훈련에 사용하진 않지만, 생성된 모델이 valid data에 적합할때까지 모델을 변경하기 때문에 간접적으로 모델에 영향을 끼쳤다고 볼 수 있다.
- 그렇기 때문에 train 데이터와 valid data을 통해 생성한 모델을 최종적으로 검증하기 위해 사용하는 데이터
❗간단하게 사용하는 경우는 test data를 별도로 사용하지 않고, valid data를 test data라는 이름으로 진행하는 경우도 있다.
코드 적용 예시
데이터 읽어오기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import pandas as pd import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.optim as optim import warnings warnings.filterwarnings('ignore') torch.manual_seed(100) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 원본 데이터 df_boston = pd.read_csv("boston_house.csv", index_col=0)데이터 전처리
- 데이터프레임과 시리즈로 구분
1 2 3 4
# boston : 데이터프레임(테이블) boston = df_boston.drop('MEDV', axis=1) # target: 시리즈(컬럼) target = df_boston.pop('MEDV')- train과 test 데이터 나누기
1 2 3 4 5 6 7 8 9 10 11
# input/target 지정 X = boston.values y = target.values X.shape, y.shape # ((506, 13), (506,)) # Train 모델 학습 # Test 모델 검증 # test_size : train과 test의 비율 (0.2인 경우 train 8, test2) # random_state: 섞을 때 동일한 난수로 섞음 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) X_train.shape, X_test.shape, y_train.shape, y_test.shape # ((404, 13), (102, 13), (404,), (102,))
- 스케일링 진행
1 2 3
sc = MinMaxScaler() X_train = sc.fit_transform(X_train) X_test = sc.fit_transform(X_test)
- torch tensor로 변환
1 2 3 4 5 6
X_train_ts = torch.FloatTensor(X_train) X_test_ts = torch.FloatTensor(X_test) y_train_ts = torch.FloatTensor(y_train).view(-1, 1) y_test_ts = torch.FloatTensor(y_test).view(-1, 1) X_train_ts.size(), X_test_ts.size(), y_train_ts.size(), y_test_ts.size()
선형회귀 모형 생성
모델 class 정의
1 2 3 4 5 6
class LinearReg(nn.Module): def __init__(self, input_size, output_size): super().__init__() self.fc1 = nn.Linear(input_size, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, output_size)
1 2 3 4 5 6 7
# 순방향 전파 정의 def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) output = self.fc3(x) return output
model instance 생성
1 2
model = LinearReg(X_train.shape[1], 1).to(device) model
손실함수/optimizer 정의
1 2
criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001)
Dataset Loader 생성
1 2
train_ds = torch.utils.data.TensorDataset(X_train_ts, y_train_ts) train_loader = torch.utils.data.DataLoader(train_ds, batch_size=32, shuffle=True)
Train set으로 훈련 수행
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
# 손실 값 저장 Loss = [] # 모델이 훈련할 총 epoch 수 num_epochs = 100 for epoch in range(num_epochs): for x, y in train_loader: # x: 입력 데이터, y: 정답 레이블 x, y = x.to(device), y.to(device) # yhat: 모델이 예측한 값 yhat = model(x) # loss: 손실 값 loss = criterion(yhat, y) # 가중치 업데이트: 그래디언트 0으로 초기화하여 축적 방지 optimizer.zero_grad() # 손실 값에 대한 그래디언트를 역전파 -> 손실함수의 미분값 계산 loss.backward() # 역전파에서 계산된 그래디언트를 사용하여 모델의 매개변수 업데이트 optimizer.step() print("epoch {} loss: {:.4f}".format(epoch+1, loss.item())) Loss.append(loss.item()) print("total : {}".format(Loss))Test set으로 모델 평가
- criterion 으로 손실값 확인
1
criterion(model(X_test_ts.to(device)), y_test_ts.to(device)).item()
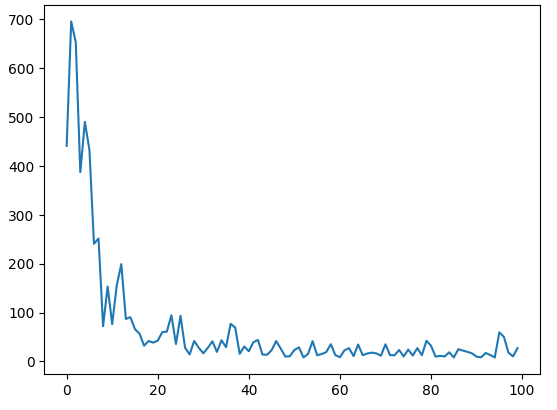
- Loss 시각화
1
plt.plot(Loss)
- criterion 으로 손실값 확인
Test set으로 예측
1 2
y_pred= model(X_test_ts.to(device)).cpu().detach().numpy() y_pred.shape # (102, 1)
평가
MSE, R2 계산
1 2 3 4 5 6 7
from sklearn.metrics import mean_squared_error, r2_score print('MSE : {}'.format(mean_squared_error(y_test, y_pred)) # MSE : 34.30465347918625 print('R2: {}'.format(r2_score(y_test, y_pred))) # R2: 0.5787140970108864True vs. Predicted 시각화
1 2 3 4 5
plt.scatter(y_test, y_pred) plt.plot(y_test, y_test, color='red') plt.xlabel("True Price") plt.ylabel("Predicted Price") plt.show()