NL to SQL - SQL 쿼리 없이 자연어로 DB 조회하기 (with AGENT)
[ NL to SQL ] SQL 쿼리 없이 자연어로 DB 조회하기 (with AGENT)
LangChain version 2의 튜토리얼에서 Build a Question/Answering system over SQL data 을 해보고 간단히 정리해보았습니다.
주요 내용은 두개의 step으로 구분됩니다.
- SQL Database에 쿼리가 아닌 자연어를 통해 쿼리 없이 DB 조회를 수행한다.
- 이 과정을 Agent로 더 간단히 한다!
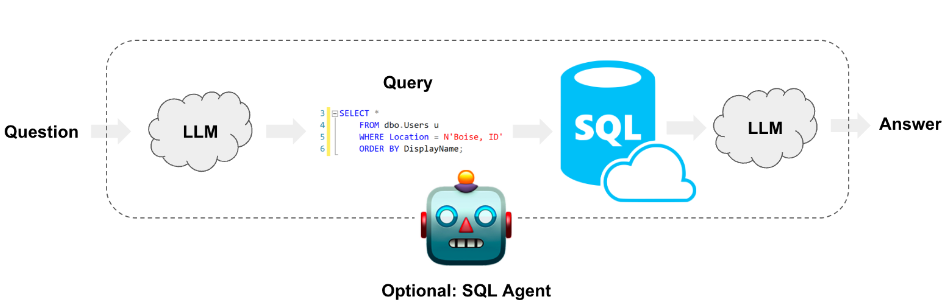
과정은 아래와 같은 순서로 진행됩니다.
- 사용자로부터 요청을 자연어로 입력받아, 이를 처리할 수 있는 query를 생성한다.
- SQL 쿼리를 수행한다.
- 쿼리 결과를 이용해 사용자에게 자연어로 답변한다.
저는 Agent로 수행하는 방법만 정리해보겠습니다!
chain+tool 이용한 방법
```python from operator import itemgetter from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_community.utilities import SQLDatabase from langchain_openai import ChatOpenAI from langchain.chains import create_sql_query_chain from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool db = SQLDatabase.from_uri("sqlite:///Chinook.db") llm = ChatOpenAI(model="gpt-3.5-turbo-0125") # chain = create_sql_query_chain(llm, db) # print(chain.get_prompts()[0].pretty_print()) # response = chain.invoke({"question" : "How many employees are there?"}) # print(response) # print(db.run(response)) write_query = create_sql_query_chain(llm, db) execute_query = QuerySQLDataBaseTool(db=db) # # chain = write_query | execute_query # # print(chain.invoke({"question": "How many employees are there"})) answer_prompt = PromptTemplate.from_template( """ Given the following user question, corresponding SQL Query, and SQL result, answer the user question. Question : {question} SQL Query : {query} SQL Result : {result} Answer: """ ) chain = ( RunnablePassthrough.assign(query=write_query).assign( result = itemgetter("query") | execute_query ) | answer_prompt | llm | StrOutputParser() ) print(chain.invoke({"question": "How many employees are there"})) ```SetUp
1
pip install --upgrade --quiet langchain langchain-community langchain-openai faiss-cpu
STEP 1. 데이터 준비
테스트를 위해 간단한 sample data를 이용했습니다.
DBMS는 SQLite를 사용했으며, 스키마는 Chinook Database를 이용했습니다.
Chinook Database?
- Chinook Database는 주로 관계형 데이터베이스 시스템의 학습 및 실습을 위해 사용되는 예제 데이터베이스입니다.
- 이 데이터베이스는 음악 상점의 정보를 모델링하며, 다양한 데이터베이스 관리 시스템 (DBMS)에서 사용할 수 있습니다.
[준비 과정] ( database guide 참고)
- Save this file as
Chinook_Sqlite.sql - Run
sqlite3 Chinook.db - Run
.read Chinook.sql
위 그림처럼 폴더에 Chinook_Sqlite.sql을 통해 .read와 Chinook.db가 생성되었습니다.
Chinook.db를 이용하여 SQLDatabase를 통해 SQL이 잘 들어왔는지 확인해봅니다.
1
2
3
4
5
6
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
출력이 아래와 같이 나오면 정상입니다!
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Step 2. LLM 초기화
1
2
3
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
Agent에서 사용할 llm을 초기화 해줍니다.
저는 gpt-4o를 사용했었는데 가이드에서는 gpt-3.5-turbo-0125를 사용하는군요.
최종 답변을 보면 gpt-4o는 조금 더 상세한 답변을, gpt-3.5-turbo-0125는 간결하고 명확한 답변을 주는 차이가 있었습니다.
Step 3. 툴킷 준비
랭체인에 있는 SQL Agent 툴킷을 이용합니다. SQL DB와 유연하게 상호작용하는 툴들을 제공해줍니다.
- DB 스키마 뿐만이 아니라 DB의 내용(content)까지도 기반을 두어 질문에 답변합니다.
- 쿼리 생성 후, 생성한 쿼리에 오류가 있다면 수행가능한(올바른) 쿼리로 계속 재생성합니다.
- 사용자 질문에 답변할 수 있도록 반복적으로 DB에 쿼리를 수행합니다.
- 관련된 테이블의 스키마를 검색하여 사용하기 때문에, 토큰을 절약할 수 있습니다.
1
2
3
4
5
6
7
from langchain_community.agent_toolkits import SQLDatabaseToolkit
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
tools = toolkit.get_tools()
tools
SQLDatabaseToolkit 툴킷은 여러 기능을 가집니다. => SQLDatabaseToolkit
- 쿼리의 생성과 수행
- 쿼리 문법 오류 검증
- 테이블 상세 설명 반환
- 등..
[QuerySQLDataBaseTool(description="Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.", db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x113403b50>),
InfoSQLDatabaseTool(description='Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x113403b50>),
ListSQLDatabaseTool(db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x113403b50>),
QuerySQLCheckerTool(description='Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x113403b50>, llm=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x115b7e890>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x115457e10>, temperature=0.0, openai_api_key=SecretStr('**********'), openai_proxy=''), llm_chain=LLMChain(prompt=PromptTemplate(input_variables=['dialect', 'query'], template='\n{query}\nDouble check the {dialect} query above for common mistakes, including:\n- Using NOT IN with NULL values\n- Using UNION when UNION ALL should have been used\n- Using BETWEEN for exclusive ranges\n- Data type mismatch in predicates\n- Properly quoting identifiers\n- Using the correct number of arguments for functions\n- Casting to the correct data type\n- Using the proper columns for joins\n\nIf there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.\n\nOutput the final SQL query only.\n\nSQL Query: '), llm=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x115b7e890>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x115457e10>, temperature=0.0, openai_api_key=SecretStr('**********'), openai_proxy='')))]
Step 4. 시스템 프롬프트 작성
Agent가 잘 수행하기 위해 우리가 원하는 목적을 담은 시스템 프롬프트를 작성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_core.messages import SystemMessage
SQL_PREFIX = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
To start you should ALWAYS look at the tables in the database to see what you can query.
Do NOT skip this step.
Then you should query the schema of the most relevant tables."""
system_message = SystemMessage(content=SQL_PREFIX)
요약하자면, 에이전트의 목적은 SQL DB와 상호작용하는 것이며, 질문이 들어왔을 때 SQL 쿼리를 만들어서 수행하고 답변해라. 특별히 요청이 없는 한 5개 이하의 데이터만 반환하고, SELECT 외의 INSERT, UPDATE, DELETE, DROP 명령어는 수행하지 마라. 등 수행 시 유의할 지시사항들 입니다.
Step 5. 에이전트 생성
1
2
3
4
from langchain_core.messages import HumanMessage
from langgraph.prebuilt import create_react_agent
agent_executor = create_react_agent(llm, tools, messages_modifier=system_message)
추적을 위해 langgraph를 이용해서 react agent를 생성해줍니다~!
SQLDatabaseToolkit 툴킷으로 할당한 tools과 openai로 생성한 llm과 위에서 작성한 system prompt를 할당해줍니다.
Step 6. 실행
어느 나라의 소비자가 가장 많은 돈을 사용했는지에 대해 질문해보았습니다.
1
2
3
4
5
for s in agent_executor.stream(
{"messages": [HumanMessage(content="Which country's customers spent the most?")]}
):
print(s)
print("----")
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_vnHKe3oul1xbpX0Vrb2vsamZ', 'function': {'arguments': '{"query":"SELECT c.Country, SUM(i.Total) AS Total_Spent FROM customers c JOIN invoices i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY Total_Spent DESC LIMIT 1"}', 'name': 'sql_db_query'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 53, 'prompt_tokens': 557, 'total_tokens': 610}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-da250593-06b5-414c-a9d9-3fc77036dd9c-0', tool_calls=[{'name': 'sql_db_query', 'args': {'query': 'SELECT c.Country, SUM(i.Total) AS Total_Spent FROM customers c JOIN invoices i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY Total_Spent DESC LIMIT 1'}, 'id': 'call_vnHKe3oul1xbpX0Vrb2vsamZ'}])]}}
----
{'action': {'messages': [ToolMessage(content='Error: (sqlite3.OperationalError) no such table: customers\n[SQL: SELECT c.Country, SUM(i.Total) AS Total_Spent FROM customers c JOIN invoices i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY Total_Spent DESC LIMIT 1]\n(Background on this error at: https://sqlalche.me/e/20/e3q8)', name='sql_db_query', id='1a5c85d4-1b30-4af3-ab9b-325cbce3b2b4', tool_call_id='call_vnHKe3oul1xbpX0Vrb2vsamZ')]}}
----
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_pp3BBD1hwpdwskUj63G3tgaQ', 'function': {'arguments': '{}', 'name': 'sql_db_list_tables'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 699, 'total_tokens': 711}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-04cf0e05-61d0-4673-b5dc-1a9b5fd71fff-0', tool_calls=[{'name': 'sql_db_list_tables', 'args': {}, 'id': 'call_pp3BBD1hwpdwskUj63G3tgaQ'}])]}}
----
{'action': {'messages': [ToolMessage(content='Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track', name='sql_db_list_tables', id='c2668450-4d73-4d32-8d75-8aac8fa153fd', tool_call_id='call_pp3BBD1hwpdwskUj63G3tgaQ')]}}
----
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_22Asbqgdx26YyEvJxBuANVdY', 'function': {'arguments': '{"query":"SELECT c.Country, SUM(i.Total) AS Total_Spent FROM Customer c JOIN Invoice i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY Total_Spent DESC LIMIT 1"}', 'name': 'sql_db_query'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 53, 'prompt_tokens': 744, 'total_tokens': 797}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-bdd94241-ca49-4f15-b31a-b7c728a34ea8-0', tool_calls=[{'name': 'sql_db_query', 'args': {'query': 'SELECT c.Country, SUM(i.Total) AS Total_Spent FROM Customer c JOIN Invoice i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY Total_Spent DESC LIMIT 1'}, 'id': 'call_22Asbqgdx26YyEvJxBuANVdY'}])]}}
----
{'action': {'messages': [ToolMessage(content="[('USA', 523.0600000000003)]", name='sql_db_query', id='f647e606-8362-40ab-8d34-612ff166dbe1', tool_call_id='call_22Asbqgdx26YyEvJxBuANVdY')]}}
----
{'agent': {'messages': [AIMessage(content='Customers from the USA spent the most, with a total amount spent of $523.06.', response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 819, 'total_tokens': 839}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'stop', 'logprobs': None}, id='run-92e88de0-ff62-41da-8181-053fb5632af4-0')]}}
----
agent가 여러 tool을 이것 저것 사용해서 답변을 생성하는 과정을 볼 수 있습니다.
먼저 sql_db_query툴을 이용해 쿼리를 만들었는데, customers라는 테이블이 없어서 오류가 났군요.
그래서 sql_db_list_tables툴을 이용해 이용 가능한 테이블 목록을 불러옵니다.
그 다음 sql_db_schema 툴을 통해 필요한 테이블 목록을 추출하고, DDL을 불러옵니다.
그리고나서 다시 sql_db_query을 통해 알맞은 쿼리를 다시 만들고, 수행해서 "[('USA', 523.0600000000003)]"라는 결과를 반환받았습니다.
그 후 최종적으로 Customers from the USA spent the most, with a total amount spent of $523.06. 답변을 생성해주는군요.
이 과정을 위처럼 프린트해서 확인할 수도 있지만 Langgraph를 걸어두었기 때문에, LangSmith에서도 확인할 수 있습니다.
- LangSmith 과정 : https://smith.langchain.com/public/3c4d0578-34ad-4ff9-891d-f2042bd18f63/r
링크를 따라 들어가보시면 각 tool에서 사용하는 prompt까지도 실제로 볼 수 있어 디버깅이나 중간에 어디서 이상하게 빠졌는지 확인하는 데 용이할 것 같아요 ㅎㅎ
전체코드
```` ```python from langchain_community.agent_toolkits import SQLDatabaseToolkit from langchain_community.utilities import SQLDatabase from langchain_openai import ChatOpenAI from langchain_core.messages import SystemMessage, HumanMessage from langgraph.prebuilt import create_react_agent db = SQLDatabase.from_uri("sqlite:///Chinook.db") llm = ChatOpenAI(model="gpt-4o") toolkit = SQLDatabaseToolkit(db=db, llm=llm) tools = toolkit.get_tools() SQL_PREFIX = """You are an agent designed to interact with a SQL database. Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer. Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results. You can order the results by a relevant column to return the most interesting examples in the database. Never query for all the columns from a specific table, only ask for the relevant columns given the question. You have access to tools for interacting with the database. Only use the below tools. Only use the information returned by the below tools to construct your final answer. You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again. DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database. To start you should ALWAYS look at the tables in the database to see what you can query. Do NOT skip this step. Then you should query the schema of the most relevant tables.""" system_message = SystemMessage(content=SQL_PREFIX) agent_executor = create_react_agent(llm, tools, messages_modifier=system_message) for s in agent_executor.stream( { "messages": [ HumanMessage(content="Which country's customers spent the most?") ] } ): print(s) print("--------------------") ``` ````Step 7. 한발짝 더!
지금까지의 작업을 봐도 간단하지만 훌륭하게 작업을 수행하는 걸 확인할 수 있었습니다.
조금 더 복잡한 작업도 해볼까요?
테이블의 데이터로 들어있는 값(고유명사)에 대해 사용자가 정확히 질문하지 않아도, 찾아내서 사용자의 질문에 맞는 답변을 줄 수 있을까요?
예를 들어 음악 가게에 Guns N'' Roses의 앨범이 총 몇개 있는지 검색을 해보고 싶습니다.
원래는 "Guns N'' Roses" 라는 고유 명사에 대해 검색할 때, 대소문자, 오타, 띄어쓰기 등 정확하게 일치하는 데이터를 입력하지 않으면 SQL에서 쿼리 조회가 되지 않죠.
하지만 "gun and roses"와 같이 완전히 일치하진 않지만, 의미적으로 유사한 데이터를 입력해도 저희가 원하는 건지앤로지스에 대한 데이터를 검색할 수 있도록 기존 코드를 조금 변경해봅시다!
원하는 각 엔티의 고유 값을 리스트 형식으로 반환받기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import ast
import re
# 아티스트 테이블의 이름과, 앨범 테이블의 제목 목록을 list 타입으로 반환
def query_as_list(db, query):
# res: 쿼리수행 결과 문자열로 반환
res = db.run(query)
# ast.literal_eval(res): 문자열로 반환된 쿼리 결과를 파이썬 객체로 변환 -> 이중 리스트
# for sub in ast.literal_eval(res): 반복문 수행 -> 리스트 ex)[('AC/DC',), ('Accept',), ('Aerosmith',), ('Alanis Morissette',)...]
# for el in sub : 하위 리스트 반복문 수행 -> 요소 ex) ['AC/DC', 'Accept', 'Aerosmith', 'Alanis Morissette',...]
# if el: 조건 확인 -> el
res = [el for sub in ast.literal_eval(res) for el in sub if el]
return list(set(res)) # 중복 제거해서 리스트로 반환
artists = query_as_list(db, "SELECT Name FROM Artist")
albums = query_as_list(db, "SELECT Title FROM Album")
albums[:5]
['Big Ones',
'Cidade Negra - Hits',
'In Step',
'Use Your Illusion I',
'Voodoo Lounge']
retriever tool로 생성
위에서 만든 함수를 이용하여 에이전트 스스로 수행할 수 있는 리트리버 툴을 생성해줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from langchain.agents.agent_toolkits import create_retriever_tool
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 아티스트 이름 + 앨범 제목 목록을 retriever tool로 생성
vector_db = FAISS.from_texts(artists + albums, OpenAIEmbeddings())
retriever = vector_db.as_retriever(search_kwargs={"k": 5})
description = """Use to look up values to filter on. Input is an approximate spelling of the proper noun, output is \
valid proper nouns. Use the noun most similar to the search."""
retriever_tool = create_retriever_tool(
retriever,
name="search_proper_nouns",
description=description,
)
잘 만들어졌나 테스트해볼까요?
1
print(retriever_tool.invoke("gun and roses"))
Guns N' Roses
Velvet Revolver
Killers
Kill 'Em All
Angel Dust
가장 유사한 데이터로 Guns N' Roses을 잘 찾아오는군요 :) !!!
시스템 프롬프트 재작성하여 에이전트 재구성
이제 위에서 만든 retriever_tool을 기존에 사용했던 SQLDatabaseToolkit 툴킷에 추가해줍니다.
그리고 시스템 프롬프트도 조금 수정해서 에이전트를 만들어봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# SQL data toolkit 초기화
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# tool 목록 정의
tools = toolkit.get_tools()
tools.append(retriever_tool) # 아티스트이름+앨범제목 목록 retriever를 tool로 추가
# 시스템 프롬프트 작성
system = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
You have access to the following tables: {table_names}
If you need to filter on a proper noun, you must ALWAYS first look up the filter value using the "search_proper_nouns" tool!
Do not try to guess at the proper name - use this function to find similar ones.""".format(
table_names=db.get_usable_table_names()
)
system_message = SystemMessage(content=system)
# react agent 생성
agent_executor = create_react_agent(llm, tools,
messages_modifier=system_message)
처음에 주었던 시스템 프롬프트와 거의 유사하지만 뒷 부분이 조금 수정되었습니다.
고유명사에 대한 필터링이 필요한 경우, 우선적으로 search_proper_nouns 툴을 이용해서 다시 값을 반환받아, 거기서 가장 유사한 데이터로 다시 시도하라는 지시가 추가되었어요.
에이전트 실행
건지앤 로지스의 앨범이 몇개인지 물어보기 위해 gun n rose의 앨범이 몇개인지 물어봅니다.
1
2
3
4
5
6
7
8
# agent 수행
for s in agent_executor.stream(
{"messages": [
HumanMessage(content="How many albums does gun n rose have?")
]}
):
print(s)
print("-------------------")
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_7pC6XmaY0D5Uzk8r3cRCLyaj', 'function': {'arguments': '{"query":"gun n rose"}', 'name': 'search_proper_nouns'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 675, 'total_tokens': 694}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-9db3994b-94e8-4074-9d15-91efbd8dec2c-0', tool_calls=[{'name': 'search_proper_nouns', 'args': {'query': 'gun n rose'}, 'id': 'call_7pC6XmaY0D5Uzk8r3cRCLyaj'}], usage_metadata={'input_tokens': 675, 'output_tokens': 19, 'total_tokens': 694})]}}
-------------------
{'tools': {'messages': [ToolMessage(content="Guns N' Roses\n\nVelvet Revolver\n\nAngel Dust\n\nKillers\n\nKill 'Em All", name='search_proper_nouns', tool_call_id='call_7pC6XmaY0D5Uzk8r3cRCLyaj')]}}
-------------------
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_ZWAn2PaEY8GwwlSos2ebnMLD', 'function': {'arguments': '{"query":"SELECT COUNT(*) FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = \'Guns N\' Roses\')"}', 'name': 'sql_db_query'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 39, 'prompt_tokens': 726, 'total_tokens': 765}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-41fbccd6-45f3-4d20-9514-bfafc00078d4-0', tool_calls=[{'name': 'sql_db_query', 'args': {'query': "SELECT COUNT(*) FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = 'Guns N' Roses')"}, 'id': 'call_ZWAn2PaEY8GwwlSos2ebnMLD'}], usage_metadata={'input_tokens': 726, 'output_tokens': 39, 'total_tokens': 765})]}}
-------------------
{'tools': {'messages': [ToolMessage(content='Error: (sqlite3.OperationalError) near "Roses": syntax error\n[SQL: SELECT COUNT(*) FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = \'Guns N\' Roses\')]\n(Background on this error at: https://sqlalche.me/e/20/e3q8)', name='sql_db_query', tool_call_id='call_ZWAn2PaEY8GwwlSos2ebnMLD')]}}
-------------------
{'agent': {'messages': [AIMessage(content='I encountered an error in the query due to the name "Guns N\' Roses." Let me correct the query and try again.', additional_kwargs={'tool_calls': [{'id': 'call_ALv5DlKnoIaTM1wNaRK9VMsO', 'function': {'arguments': '{"query":"SELECT COUNT(*) FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = \'Guns N\'\' Roses\')"}', 'name': 'sql_db_query'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 67, 'prompt_tokens': 841, 'total_tokens': 908}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-469c16ac-5825-46b5-ac03-18310adb0468-0', tool_calls=[{'name': 'sql_db_query', 'args': {'query': "SELECT COUNT(*) FROM Album WHERE ArtistId IN (SELECT ArtistId FROM Artist WHERE Name = 'Guns N'' Roses')"}, 'id': 'call_ALv5DlKnoIaTM1wNaRK9VMsO'}], usage_metadata={'input_tokens': 841, 'output_tokens': 67, 'total_tokens': 908})]}}
-------------------
{'tools': {'messages': [ToolMessage(content='[(3,)]', name='sql_db_query', tool_call_id='call_ALv5DlKnoIaTM1wNaRK9VMsO')]}}
-------------------
{'agent': {'messages': [AIMessage(content="Guns N' Roses have 3 albums in the database.", response_metadata={'token_usage': {'completion_tokens': 14, 'prompt_tokens': 924, 'total_tokens': 938}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-f64240a8-d7f6-4b7b-8a72-11a0254f69dd-0', usage_metadata={'input_tokens': 924, 'output_tokens': 14, 'total_tokens': 938})]}}
-------------------
Langsmith의 LangGraph입니다 -> https://smith.langchain.com/public/09c17547-fa73-46e9-9dda-bfb3d3ebf43f/r
How many albums does gun n rose have?질문이 입력되니, 우선search_proper_nouns툴을 통해 답변을 받았어요.- 그 후에
sql_db_query툴을 통해Guns N' Roses의 앨범 갯수를 찾는 쿼리를 생성하는군요. - 그런데
Guns N' Roses그대로 쓰면 문법 오류가 나기 때문에 본인이 알아서Guns N'' Roses으로 변경했어요. - 다시 쿼리를 수행해서,
"[(3,)]"라는 답변을 받았군요. - 최종적으로
Guns N' Roses have 3 albums in the database.라는 답변을 반환해줍니다.
전체코드
```python import ast import re from langchain.agents.agent_toolkits import create_retriever_tool from langchain_community.agent_toolkits import SQLDatabaseToolkit from langchain_community.utilities import SQLDatabase from langchain_openai import ChatOpenAI from langchain_core.messages import SystemMessage, HumanMessage from langgraph.prebuilt import create_react_agent from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings db = SQLDatabase.from_uri("sqlite:///Chinook.db") llm = ChatOpenAI(model="gpt-3.5-turbo-0125") # 아티스트 테이블의 이름과, 앨범 테이블의 제목 목록을 list 타입으로 반환 def query_as_list(db, query): res = db.run(query) res = [el for sub in ast.literal_eval(res) for el in sub if el] res = [re.sub(r"\b\d+\b", "", string).strip() for string in res] return list(set(res)) artists = query_as_list(db, "SELECT Name FROM Artist") albums = query_as_list(db, "SELECT Title FROM Album") # 아티스트 이름 + 앨범 제목 목록을 retriever tool로 생성 vector_db = FAISS.from_texts(artists + albums, OpenAIEmbeddings()) retriever = vector_db.as_retriever(search_kwargs={"k": 5}) description = """ Use to look up values to filter on. Input is an approximate spelling of the proper noun, output is valid proper nouns. Use the noun most similar to the search. """ retriever_tool = create_retriever_tool( retriever, name="search_proper_nouns", description=description ) print(retriever_tool.invoke("gun and roses"))# SQL data toolkit 초기화 toolkit = SQLDatabaseToolkit(db=db, llm=llm) # tool 목록 정의 tools = toolkit.get_tools() tools.append(retriever_tool) # 아티스트이름+앨범제목 목록 retriever를 tool로 추가 # 시스템 프롬프트 작성 system = """You are an agent designed to interact with a SQL database. Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer. Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results. You can order the results by a relevant column to return the most interesting examples in the database. Never query for all the columns from a specific table, only ask for the relevant columns given the question. You have access to tools for interacting with the database. Only use the given tools. Only use the information returned by the tools to construct your final answer. You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again. DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database. You have access to the following tables: {table_names} If you need to filter on a proper noun, you must ALWAYS first look up the filter value using the "search_proper_nouns" tool! Do not try to guess at the proper name - use this function to find similar ones.""".format( table_names=db.get_usable_table_names() ) system_message = SystemMessage(content=system) # react agent 생성 agent_executor = create_react_agent(llm, tools, messages_modifier=system_message) # agent 수행 for s in agent_executor.stream( {"messages": [ HumanMessage(content="How many albums does gun n rose have?") ]} ): print(s) print("-------------------") ```자연어를 통해 SQL을 수행하는 NL(Natural Language) to SQL, 자연어를 통해 API를 수행하는 NL to API 등의 기술들이 존재합니다.
이를 구현하기 위해서는 여러가지 방법이 있깄지만 이번 글에서는 Langchain의 SQLDatabaseToolkit을 이용해서 Agent를 구성해서 구현하는 방법을 살펴보았습니다!
그동안 정말 머리아픈 복잡한 쿼리들을 많이 보았었는데요.. 이제 말만 잘하면 그 복잡한 몇백줄짜리 쿼리는 사라질 수 있는걸까요..?!!!!