Langchain Study | 3-2. Agents 1 - Basic
LLM(언어모델)은 단순히 질문에 대한 답변을 줄 뿐 그 이상은 할 수 없습니다. 예를 들어 검색 결과에 대해 로컬 파일에 저장한다거나, API를 수행하는 등의 Action을 취할 수 없습니다. Langchain의 Agents 모듈을 사용하면 LLM을 활용하여 더 확장된 다양한 작업들을 수행할 수 있게 해줍니다!
이번 챕터에서는 Agents 모듈에 대한 컨셉 설명과 기본적으로 적용해볼 수 있는 코드를 작성해보겠습니다!
Agents 모듈 컨셉
Agents 모듈을 설명할 때 흔히 :robot: <- 이 모양의 지능이 있어보이는 로봇을 많이 사용하는데요, 그 이유가 있습니다.
Agents는 LLM을 추론 엔진으로 사용하여, 사용자의 요청에 따라 어떤 행동을 취할지, 그 행동의 입력값은 무엇이어야 하는지를 결정해주는 시스템이기 때문입니다! 그 행동의 결과를 다시 Agent에게 전달되어서 추가 행동이 필요한지, 아니면 작업을 종료해도 되는지를 결정하는 판단도 합니다.
우리는 지금까지 체인을 구성할 때 입력 프롬프트를 구성하고, LLM을 호출하고, 결과를 보고 불충분하다면 다시 다음 작업에 최적화된 입력값이 되기 위해 출력을 변환하는 작업을 수기로 진행하였습니다. Agents 모듈을 통해서는 이 과정을 LLM의 추론으로 맡기는 것이죠.
구성
Agents 모듈을 두 개의 하위 모듈로 구성됩니다.
- Tool
- Agent
Tool
Tool은 말 그대로 다양한 도구를 의미합니다. Agents 모듈을 통해서 여러 가지 action을 취할 수 있다고 말씀드렸었는데요, 바로 그 액션을 취하는 도구가 Tool을 의미합니다. 지정된 URL로 요청을 보내거나, 지정된 경로에 파일을 읽거나 쓰는 툴도 있습니다.
따라서 Agent를 구성할 때, 목적에 맞는 툴(들)을 선택할 수 있습니다.
툴은 랭체인에서 제공하는 툴을 이용할 수도 있고, 직접 만들어서 사용할 수도 있습니다.
이번 예제에서는 제공하는 툴을 사용해보기도 하고, 직접 만들어보기도 해보겠습니다!
Agent
Agent를 선택된 툴을 가지고 그 다음 단계의 처리를 수행하는 주체입니다.
Agent에서 가장 대표적인 기법인 ReAct 기법은 아래의 흐름에 따라 진행됩니다.
- 사용자로부터 작업을 받는다.
- 준비된 Tool 중에서 어떤 Tool을 사용할지, 어떤 정보를 입력할지를 결정한다.
- Tool을 사용해 결과를 얻는다.
- 3에서 얻는 결과를 통해 목적이 달성되었는지를 평가한다.
- 에이전트가 작업을 완료했다고 판단할 수 있을 때까지 2~4 과정을 반복한다.
ReAct 기법은 모델이 문제를 이해하고, 행동을 결정하며, 결과를 바탕으로 다음 행동을 취하는 반응형 접근 방식을 사용합니다. 이 방법은 문제 해결 과정에서 모델의 논리적 추론을 강조합니다.
:bulb:이 외에도 몇 가지 기법이 있으며, 설정값에 따라 변경할 수 있습니다.
Agent 구동 방식에 대한 종류는 이번 글 마지막 부분에서 자세히 설명드리겠습니다.
이렇게 Agent는 단순히 Tool을 조작하는 역할이 아닌, 어떤 Tool을 사용하면 좋을 지 고민하고 실행하고, 결과 검증까지 스스로 하는 모듈입니다.
구현 방법
LangGraph vs AgentExecutor
Langchain에서는 Agent를 구현할 수 있는 두 가지 방법을 제공합니다.
LangGraph를 이용해서 구현하는 방법과 AgentExecutor를 이용하는 방법 두 가지가 있습니다.
Langchain verion 0.1에서 초기에는 AgentExecutor를 통해 에이전트 런타임을 구현할 수 있도록 하였습니다. 하지만 맞춤형 에이전트가 많아짐에 따라 유연하게 대응하지 못하는 문제가 있어, v0.2 부터는 LangGraph가 등장했습니다. LangGraph는 보다 유연하고 제어 가능한 런타임을 제공하며, 향후 AgentExecutor은 deprecated될 예정입니다.
LangGraph 예제
웹 검색을 통해 질문에 답변하기
:exclamation: 사전 준비
- Tavily Search api key 등록 이번 예제에서는 웹 검색을 할 수 있는 Tavily Search 엔진을 사용하기 위해 키를 획득하여, 환경변수로 설정해두어야 합니다.
- https://docs.tavily.com/ 에 회원가입 후, API Key를 획득합니다. (*Tavily is free to use for up to 1,000 API calls .)
- 획득한 key는 환경 변수
TAVILY_API_KEY로 등록합니다.
라이브러리 업데이트
1
pip install -U langchain-community langgraph langchain-anthropic tavily-python
웹 검색을 할 수 있는 Tool과 파일 저장을 할 수 있는 Tool을 이용해서, 결과를 파일로 저장하는 Agent를 구현해보도록 하겠습니다.
1. 툴 정의
먼저 검색 엔진을 선택할 수 있는 우리의 메인 툴 Tavily를 정의해보겠습니다.
1
2
3
4
5
6
7
8
9
from langchain_community.tools.tavily_search import TavilySearchResults
import os
os.environ["TAVILY_API_KEY"] = "{TAVILY_API_KEY}"
# Tool 1 정의 - Tavily
search = TavilySearchResults(max_results=10)
search_results = search.invoke("2024년 7월 개봉 영화")
print(search_results)
[{'url': 'http://www.moviechart.co.kr/rank/boxoffice', 'content': '1,604,699 명. 16,481,708,788 원. 예매하기. [박스오피스]는 실시간 발권데이터를 전일기준까지 반영하여 일별/주말/월별 등 각종 통계정보를 제공합니다. (출처 : 영화진흥위원회) 영화순위, 예매율, 누적관객 정보, 영화예매, 무료영화예매권.'}, {'url': 'http://www.cgv.co.kr/movies/pre-movies.aspx', 'content': '무비차트. 상영예정작. 이달의 추천영화 112 IMAX. 명탐정 코난-100만 달러의 펜타그램. 예매율14.5%. 99%. 2024.07.17 개봉D-3 예매. 이달의 추천영화 218 IMAX. 데드풀과 울버린.'}]
최근 개봉한 영화에 대한 정보를 url과 content를 통해 반환해줍니다.
다음은 파일 저장을 위한 툴을 얻기 위해 FileManagementToolkit 에서 가져오겠습니다.
1
2
3
4
5
6
7
8
9
10
from langchain_community.agent_toolkits import FileManagementToolkit
toolkit = FileManagementToolkit(
root_dir=str("./"),
selected_tools=["write_file"],
)
writeFileTool = toolkit.get_tools()[0]
# 툴 목록 정의
tools = [search, writeFileTool]
툴은 리스트에 담아 목록에 정의해줍니다.
2. LLM 연동
어떤 툴을 사용해야 할지 선택하고, 수행결과를 판단할 LLM을 초기화해줍니다.
1
2
3
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
3. 에이전트 정의
1
2
3
4
5
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import HumanMessage
# 에이전트 정의
agent_executor = create_react_agent(model, tools)
4. 에이전트 실행
툴을 사용할 필요가 없는 입력값과 툴을 사용해야 하는 입력값을 둘 다 넣어봅니다.
1
2
response = agent_executor.invoke({"messages": [HumanMessage(content="hi!")]})
print(response["messages"])
툴을 사용할 필요가 없는 입력값의 경우 LLM을 툴을 호출하지 않고 결과를 처리합니다.
1
[HumanMessage(content='hi!', id='0aa2be45-2bbd-4936-af98-32160567e24f'), AIMessage(content='Hello! How can I assist you today?', response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 133, 'total_tokens': 143}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_d33f7b429e', 'finish_reason': 'stop', 'logprobs': None}, id='run-daca395a-a810-4a24-8ec0-f02d73390f18-0', usage_metadata={'input_tokens': 133, 'output_tokens': 10, 'total_tokens': 143})]
웹 검색 툴과 파일 저장 툴을 사용해야 하는 쿼리로 다시 수행해봅니다.
1
2
3
4
response = agent_executor.invoke(
{"messages": [HumanMessage(content="2024년 7월 영화 개봉작품 정의해서 파일로 저장해줘.")]}
)
print(response["messages"])
랭스미스 결과를 보면 Agent는 아래의 과정을 거칩니다.
- 모델 호출:
2024년 7월 영화 개봉작품 정의해서 파일로 저장해줘.라는 질문을 통해tavilyapi 호출 결정 -> 계속 수행 - Tavily Tool 수행:
2024년 7월 영화 개봉작라고 웹에 검색 api 수행하여 출력값 획득 -> 계속 수행 - 모델 호출: 초기 사람의 요청과 웹 검색 결과를 보고, 웹 검색 결과값을 파일로 저장해야 하기 때문에 디스크에 파일로 저장하는 tool 선택 -> 계속 수행
- File Write Tool 수행: 웹검색 결과값을 지정된 경로에 저장
- 모델 호출: 지금까지 수행된 과정 보고, 파일 저장까지 확인 -> 수행 종료
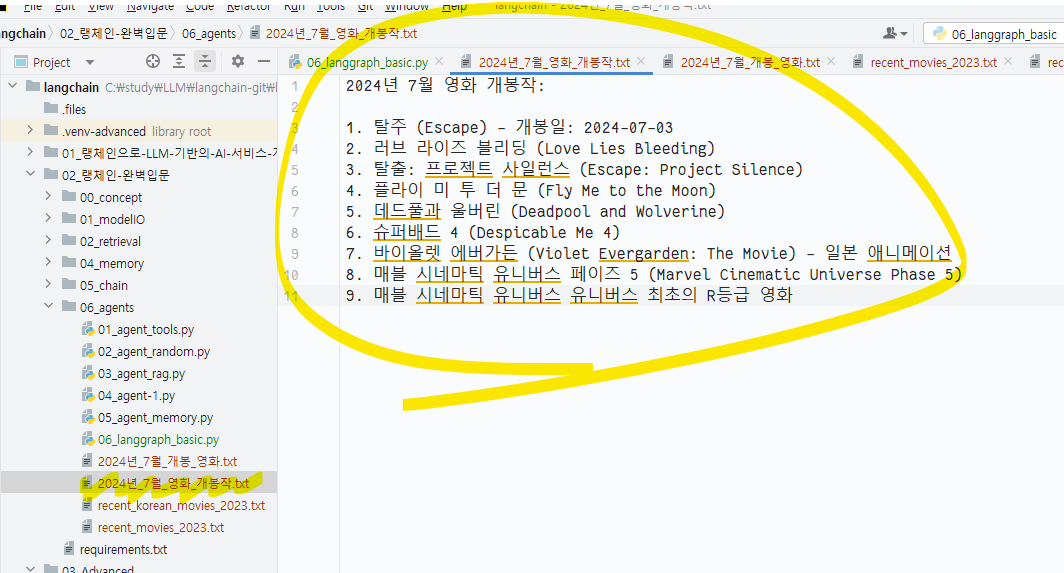
로컬에 지정된 경로에 검색 내용이 담긴 파일이 저장된 것을 확인할 수 있습니다.
직접 Tool 만들어보기
지금까지는 이미 제공되는 Tool들을 사용해서 코드를 구현해보았습니다. 이번에는 직접 원하는 Tool을 만들어서 Agent에게 작업을 시켜봅시다!
먼저 Tool을 만들기 위해, Tool의 구성 요소에 대해 알아보겠습니다.
name: Tool을 식별하기 위한 이름 ex) write_file, requests_get ..description: Tool이 무엇을 수행하는 지에 대한 간략한 설명. Agent가 해당 Tool을 선택할지에 대한 판단 자료로 사용됨args_schema: Tool이 실행 시, 파라미터값에 대한 정보 (optional but recommendedreturn_direct: 에이전트에 할당 시, True로 지정하면 지정된 도구를 호출한 뒤 에이전트 결과 중지 후 사용자에게 직접 반환
위 구조로 이름, 기능설명, 입력 스키마와 직접 반환 여부만 준비하면 @tool 데코레이터를 이용해서 쉽게 Tool을 직접 만들 수 있습니다.
🦖이름, 설명 및 JSON 스키마가 잘 선택되어 있으면 모델의 성능이 향상됩니다.
이번에는 입력되는 두 값을 곱해주는 Tool을 만들어봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# 툴 구성요소 확인
print(multiply.name) # multiply
print(multiply.description) # Multiply two numbers.
print(multiply.args) # {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
# Tool 실행해보기
print(multiply.invoke({"a": 3, "b": 4})) # 12
만든 Tool을 agent에 연결해서, 두 숫자를 입력하고 결과값을 파일로 저장해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from langchain_community.agent_toolkits import FileManagementToolkit
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
toolkit = FileManagementToolkit(
root_dir=str("./"),
selected_tools=["write_file"],
)
writeFileTool = toolkit.get_tools()[0]
# 툴 목록 정의
tools = [multiply, writeFileTool]
# 모델과 툴 연동
model = ChatOpenAI(model="gpt-4o")
# 에이전트 정의
agent_executor = create_react_agent(model, tools)
response = agent_executor.invoke(
{"messages": [HumanMessage(content="3과 4를 곱해서 연산과정을 파일로 저장해줘.")]}
)
print(response["messages"])
우리가 만든 multiply 툴과 파일 저장하는 툴인 write_file을 통해 연산 과정이 아래 그림과 같이 디스크에 파일로 저장되었습니다.
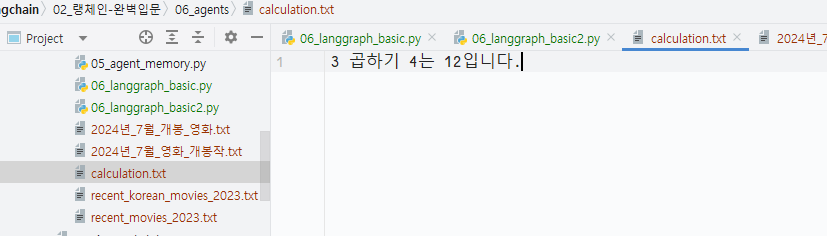
랭스미스의 결과를 보면 multiply 툴을 통해 곱셈연산을 수행하고, write_file 툴을 통해 파일로 저장한 과정을 확인할 수 있습니다.
AgentExecutor 예제
구글 검색 결과를 로컬 파일로 저장하기
:exclamation:사전준비
이번 예제에서는 구글 검색을 할 수 있는 Tool인
serpapi를 사용하기 위해 token이 환경변수에 저장되어 있어야 합니다.이를 위해 https://serpapi.com/ 홈페이지에서 회원가입 후, 무료버전을 구독하여 token을 받아 환경변수에
SERPAPI_API_KEY환경변수로 설정을 해두는 작업이 필요합니다.
구글 검색을 할 수 있는 Tool과 파일 저장을 할 수 있는 Tool을 이용해서, 결과를 파일로 저장하는 Agents를 구현해보도록 하겠습니다.
agent_tools.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.chat_models import ChatOpenAI
from langchain.tools.file_management import WriteFileTool #←파일 쓰기를 할 수 있는 Tool을 가져오기
chat = ChatOpenAI(
temperature=0, #← temperature를 0으로 설정해 출력의 다양성을 억제
model="gpt-3.5-turbo"
)
tools = load_tools( #← LangChain에 준비된 Tool을 로드
[
"requests_all", #← 특정 URL의 결과를 얻는 Tool인 requests를 로드
"serpapi" #← 구글 검색을 수행하는 Tool
],
# llm=chat
)
tools.append(WriteFileTool(root_dir="./")) #←파일 쓰기를 할 수 있는 Tool을 추가
agent = initialize_agent( #← Agent를 초기화
tools=tools, #← Agent가 사용할 수 있는 Tool의 배열을 설정
llm=chat, #← Agent가 사용할 언어 모델을 지정
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, #← Agent 유형 선택
verbose=True #← 실행 중 로그를 표시
)
result = agent.run("판나코타 레시피를 검색해 cookbook.txt 파일에 한국어로 저장하세요.") #←실행 결과를 파일에 저장하도록 지시
print(f"실행 결과: {result}")
load_tools을 통해 필요한 Tool을 불러옵니다.- 저는 랭체인에서 제공하는
requests_all과serpapi툴을 불러왔습니다. WriteFileTool은 load_tools을 통해 가져올 수 없기 때문에, append하여 tool에 추가하였습니다.
- 저는 랭체인에서 제공하는
initialize_agent를 통해 매개변수를 받아 Agent를 구성합니다.tools: Agent에서 사용할 Tool을 배열로 지정llm: Agent에서 사용할 언어모델을 지정agent: 어떤 방식으로 Agent 방식을 구동할 지 설정verbose: Agent가 Tool을 어떻게 사용하는지 등 진행 상황을 기록하는 설정
코드를 수행하면 아래와 같이 결과가 나타납니다.
> Entering new AgentExecutor chain...
Thought: I need to search for the "판나코타 레시피" and save it in Korean to a file named "cookbook.txt".
Action:
`
{
"action": "Search",
"action_input": "판나코타 레시피"
}
`
Observation: 젤라틴이 불려지는 동안 생크림과 우유를 준비할거에요. 생크림 100ml, 우유 200ml 를 더해 총 300ml를 잘 섞어줍니다 .
Thought:I found the recipe for Panna Cotta. Now, I will save it in Korean to a file named "cookbook.txt".
Action:
`
{
"action": "write_file",
"action_input": {
"file_path": "cookbook.txt",
"text": "젤라틴이 불려지는 동안 생크림과 우유를 준비할거에요. 생크림 100ml, 우유 200ml 를 더해 총 300ml를 잘 섞어줍니다."
}
}
`
Observation: File written successfully to cookbook.txt.
Thought:I have successfully saved the Panna Cotta recipe in Korean to the file named "cookbook.txt."
Action:
`
{
"action": "Final Answer",
"action_input": "The Panna Cotta recipe has been saved in Korean to the 'cookbook.txt' file."
}
`
> Finished chain.
실행 결과: The Panna Cotta recipe has been saved in Korean to the 'cookbook.txt' file.
Entering new AgentExecutor chain...을 통해 Agent의 실행이 시작되었음을 알려줍니다.
Thought, Action, Observation이 반복적으로 찍히는 것을 확인할 수 있습니다.
Thought: Agent의 사고과정을 출력합니다. Agent가 수행해야 할 일, 현재까지 작업에 대한 판단 등의 과정을 출력합니다.Action: Tool 실행에 대한 정보를 표현하며, json으로 수행되는 Tool의 이름과 입력값을 출력합니다.1 2 3 4
{ "action" : "{Tool의 이름}", "action_input": {Tool에 대한 입력값} }
Observation: Tool 수행의 결과를 표현합니다.
Agent는 Tool을 통해 얻은 결과가 원하는 답과 일치하는 지 판단하고, 검증한 결과를 달성할 수 있다고 판단되면 그 결과를 Final Answer로 출력하고 수행을 중지합니다.
로컬 파일에 지정한 경로에 cookbook.txt 파일이 생성되어, 판나코타의 레시피가 저장되었습니다.
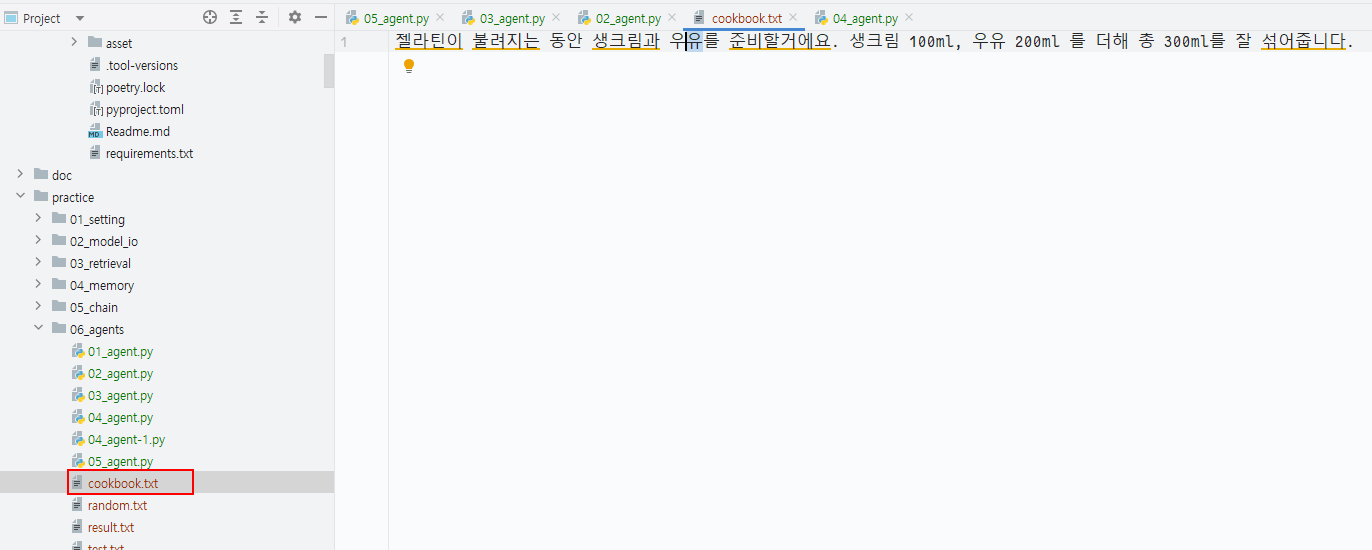
레시피가 중간에 짤렸네요 ㅎㅎ..
직접 Tool 만들어보기
지금까지는 Agents 모듈에서 이미 제공되는 Tool들을 사용해서 코드를 구현해보았습니다. 이번에는 직접 원하는 Tool을 만들어서 Agent에게 작업을 시켜봅시다!
먼저 Tool을 만들기 위해, Tool의 구성 요소에 대해 알아보겠습니다.
name: Tool을 식별하기 위한 이름 ex) write_file, requests_get ..description: Tool이 무엇을 수행하는 지에 대한 간략한 설명. Agent가 해당 Tool을 선택할지에 대한 판단 자료로 사용됨func: Tool이 실제로 작동할 때 처리하는 함수
위 구조로 이름, 기능설명, 실행 함수만 준비하면 쉽게 Tool을 직접 만들 수 있습니다.
이번에는 특정 숫자 이상의 임의의 숫자를 생성하는 Tool을 만들어봅시다.
agent_random.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import random
from langchain.agents import AgentType, initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langchain.tools.file_management import WriteFileTool #←파일 쓰기를 할 수 있는 Tool을 가져오기
chat = ChatOpenAI(
temperature=0, #← temperature를 0으로 설정해 출력의 다양성을 억제
model="gpt-3.5-turbo"
)
tools = []
tools.append(WriteFileTool(root_dir="./")) #←파일 쓰기를 할 수 있는 Tool을 추가
def min_limit_random_number(min_number):
return random.randint(int(min_number), 100000)
tools.append(
Tool(
name="Random",
description="입력된 숫자 이상의 100000이하의 임의의 숫자를 생성할 수 있습니다.",
func=min_limit_random_number
)
)
agent = initialize_agent( #← Agent를 초기화
tools,
chat,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, #← Agent 유형 선택
verbose=True #← 실행 중 로그를 표시
)
result = agent.run("10 이상의 난수를 생성해 randon.txt 파일에 저장해주세요.") #←실행 결과를 파일에 저장하도록 지시
print(f"실행 결과: {result}")
min_limit_random_number에 입력받은 숫자 이상의 랜덤한 숫자를 생성하여 반환하는 함수를 정의하였습니다.- 이 함수를 가지고
Tool에 이름과 설명, 그리고 생성한min_limit_random_number함수를 파라미터 값으로 지정하여 Tool을 생성하였습니다. - agent에는 기존과 마찬가지로 tools를 통해 파일 읽기/쓰기 Tool과 직접 생성한 Tool을 할당해주었습니다.
코드를 수행하면, 다음의 결과가 출력됩니다.
> Entering new AgentExecutor chain...
Thought: I will generate a random number greater than or equal to 10 and save it to a file named "random.txt".
Action:
`
{
"action": "Random",
"action_input": "10"
}
`
Observation: 38764
Thought:Action:
`
{
"action": "write_file",
"action_input": {
"file_path": "random.txt",
"text": "38764",
"append": false
}
}
`
Observation: File written successfully to random.txt.
Thought:I have generated a random number greater than or equal to 10 and saved it to a file named "random.txt". Would you like me to do anything else?
> Finished chain.
실행 결과: I have generated a random number greater than or equal to 10 and saved it to a file named "random.txt". Would you like me to do anything else?
Process finished with exit code 0
- 먼저 Agent에서 해야 할 일을 정의하고, Tool을 선택합니다.
- 생성한 Tool인 Random 툴을 선택하고, 입력값은 10을 줍니다.
- min_limit_random_number 함수가 수행되고 결과값이 38764으로 반환됩니다.
- 다시 Agent는 write_file 툴을 선택해 Action을 수행하여, 입력값을 스스로 생성하여 수행합니다.
- 38764을 기재한 random.txt 파일을 지정한 경로에 저장하고, 목적을 달성했음을 판단하여 chain을 종료합니다.
이렇게 직접 Tool을 만들어서 랭체인에 없는 기능을 Agent에 추가할 수 있습니다.
Agent 구동 방식 종류
LangChain의 Agent 모듈에는 다양한 구동 방식이 있습니다. 그 중 두 가지 주요 방법인 ReAct 방법과 OpenAI Function Calling 방법을 설명해드리겠습니다.
ReAct 방법
ReAct 방법은 언어 모델이 문제를 해결하기 위해 행동(Act)과 반응(React)을 결합하는 접근 방식입니다. 언어 모델은 먼저 문제를 이해하고, 필요한 행동을 결정한 후, 그 결과를 기반으로 다음 행동을 취합니다.
AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION- 주로 대화형(챗봇) 환경에서 사용됩니다.
- 사용자가 대화 형식으로 질문을 하거나 문제를 제시할 때 모델이 반응하는 방식입니다.
- 예를 들어, 챗봇과의 대화 중에 사용자가 질문을 던지면, 챗봇이 주어진 정보만으로 답변을 제공하는 상황을 상상할 수 있습니다.
AgentType.ZERO_SHOT_REACT_DESCRIPTION- 일반적인 텍스트 입력 환경에서 사용됩니다.
- 대화형 형식이 아닌, 텍스트 블록이나 문서 형태의 입력을 처리할 때 사용됩니다.
- 예를 들어, 특정 문제에 대한 텍스트 설명이 주어지면, 모델이 그 설명을 바탕으로 문제를 해결하는 상황을 생각할 수 있습니다.
AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION- 이 방식은 구조화된 형식으로 주어진 문제를 해결합니다.
- 예를 들어, 테이블이나 목록 형태의 정보를 사용할 때 유용합니다. 모델은 구조화된 데이터를 바탕으로 행동을 결정합니다.
- 여러가 툴을 사용할 때 사용합니다.
OpenAI Function Calling 방법
OpenAI Function Calling 방법은 언어 모델이 특정 함수를 호출하여 문제를 해결하는 방식입니다. 모델은 주어진 함수를 사용해 직접적인 해결책을 찾고 결과를 반환합니다.
AgentType.OPENAI_FUNCTIONS- 단일 함수를 호출하여 문제를 해결합니다.
- 사용자가 정의한 하나의 함수만 사용하여 작업을 수행합니다.
AgentType.OPENAI_MULTI_FUNCTIONS- 여러 함수를 호출하여 문제를 해결합니다.
- 다양한 함수를 사용하여 복잡한 문제를 단계별로 해결할 수 있습니다.
차이점
- ReAct 방법은 모델이 문제를 이해하고, 행동을 결정하며, 결과를 바탕으로 다음 행동을 취하는 반응형 접근 방식을 사용합니다. 이 방법은 문제 해결 과정에서 모델의 논리적 추론을 강조합니다.
- OpenAI Function Calling 방법은 특정 함수를 호출하여 문제를 해결합니다. 이 방법은 함수의 직접적인 호출을 통해 문제를 해결하며, 함수의 정확한 사용과 호출 순서가 중요합니다.
이렇게 각 방법은 문제 해결을 위한 접근 방식과 사용 시나리오가 다릅니다. 상황에 맞는 적절한 방법을 선택하여 사용할 수 있습니다.
:pencil2:️ Wrap up!
Agent를 만들어서 사용해보니, 분명 편한 기능이기도 하지만 agent.run에 입력하는 프롬프트에 따라 출력이 원하는 대로 안나오는 경우가 많은 것 같기도 합니다.
예를 들어 판나코타의 레시피는 길게 존재하지만, 한 문장밖에 얻어내지 못했던 첫번째 예제처럼 말이죠.
랭체인을 공부하면 할수록 프롬프트의 입력과 상세 조정이 결과에 큰 영향을 준다는 것을 배우네요!
다음은 우리가 배웠던 Retriever과 Memory 모듈을 Agent에 적용해서 주어진 증강 지식을 통해 LLM의 답변을 가져오게도 해보고, 맥락을 이해하는 대화형 LLM도 구현해보겠습니다!