Langchain Study | 3-2. Retrieval4- RetrievalQA
지난 챕터에서는 RAG 기법을 이용해서 QA 시스템을 개발해보았는데요, 벡터 데이터베이스를 호출하고, 유사도 검색 수행 후, 해당 결과값과 질문을 결합하는 프롬프트를 생성하고, 언어 모델을 호출하여 프롬프트를 전달하는 등 여러 과정을 거쳤습니다.
이번 챕터에서는 위 과정을 보다 간단하게 처리할 수 있는 RetrievalQA 모듈을 소개해드리겠습니다!
RetrievalQA란?
RAG를 이용한 QA 시스템에서는 아래와 같은 비슷한 구현의 패턴이 어느정도 존재합니다.
입력된 질문 기반 벡터 데이터베이스에서 검색
프롬프트 구축
- 프롬프트의 구조: 질문 + 출처가 되는 문장 + 출처가 되는 문장을 바탕으로 질문에 답하도록 지시하는 문장
언어모델 호출 처리
위와 같은 반복되는 구현 과정을 RetrievalQA에서 처리해줌으로써 개발자는 QA 시스템에서의 공통적인 부분을 불필요하게 반복하여 코드로 작성하지 않을 수 있습니다.
RetrievalQA를 이용해 다시 구현해보기
기존에 구현했던 벡터 데이터베이스에서 검색을 수행하여, LLM을 통해 답변을 전달받는 코드인 query.py 를 RetievalQA를 이용해 다시 구현해보도록 하겠습니다.
04_retrievalQA.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# LLM 언어모델 정의
chat = ChatOpenAI(model="gpt-3.5-turbo")
# 임베딩 모델 정의
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 벡터 데이터 베이스 정의
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings
)
retriever = database.as_retriever() #← 데이터베이스를 Retriever로 변환
qa = RetrievalQA.from_llm( #← RetrievalQA를 초기화
llm=chat, #← Chat models를 지정
retriever=retriever, #← Retriever를 지정
return_source_documents=True #← 응답에 원본 문서를 포함할지를 지정
)
# 정의한 RetrievalQA에 파라미터로 질 작성
result = qa("비행 자동차의 최고 속도를 알려주세요")
print(result["result"]) #← 응답을 표시
# 도심에서 비행 자동차가 비행하는 경우 최대 속도는 시속 150km이며, 도시 외의 지역에서 비행 자동차가 비행하는 경우 최대 속도는 시속 250km입니다.
print(result["source_documents"]) #← 원본 문서를 표시
"""
[Document(
page_content='제2조(정의)\n이 법에서 "비행자동차"라 함은 지상 및 공중을 이동할 수 있는 능력을 가진 차량을 말한다....',
metadata={'source': './sample.pdf', 'file_path': './sample.pdf', 'page': 3, 'total_pages': 12, 'format': 'PDF 1.7', 'title': '하늘을 나는 자동차 관련 법제도', 'author': '', 'subject': '', 'keywords': ', docId:825DD61FFAE9658C7293B36CB13F138C', 'creator': 'Microsoft Office Word', 'producer': 'Aspose.Words for .NET 23.11.0', 'creationDate': 'D:20231207125109Z', 'modDate': "D:20231211174122+09'00'", 'trapped': ''}),
Document(...), ...
]
"""
as_retriever메서드를 통해 database를 Retriever로 형식으로 변환합니다. Retriever는 간단히 설명하면 특정 검색을 할 때 Document의 배열을 반환하는 모듈입니다.
RetrievalQA.from_llm을 실행하여 위에서 정의한 llm과 retriever를 지정하고, return_source_documents에 True를 설정하여 실행 시 답변 뿐 아니라 참고한 문서도 함께 가져옵니다. 정의한 RetrievalQA에 파라미터로 질문을 입력하여 llm으로부터 결과를 반환받을 수 있습니다.
RetrievalQA 사용 전 후 비교
RetrievalQA를 사용하지 않을 때와 소스 코드를 비교해봅시다.
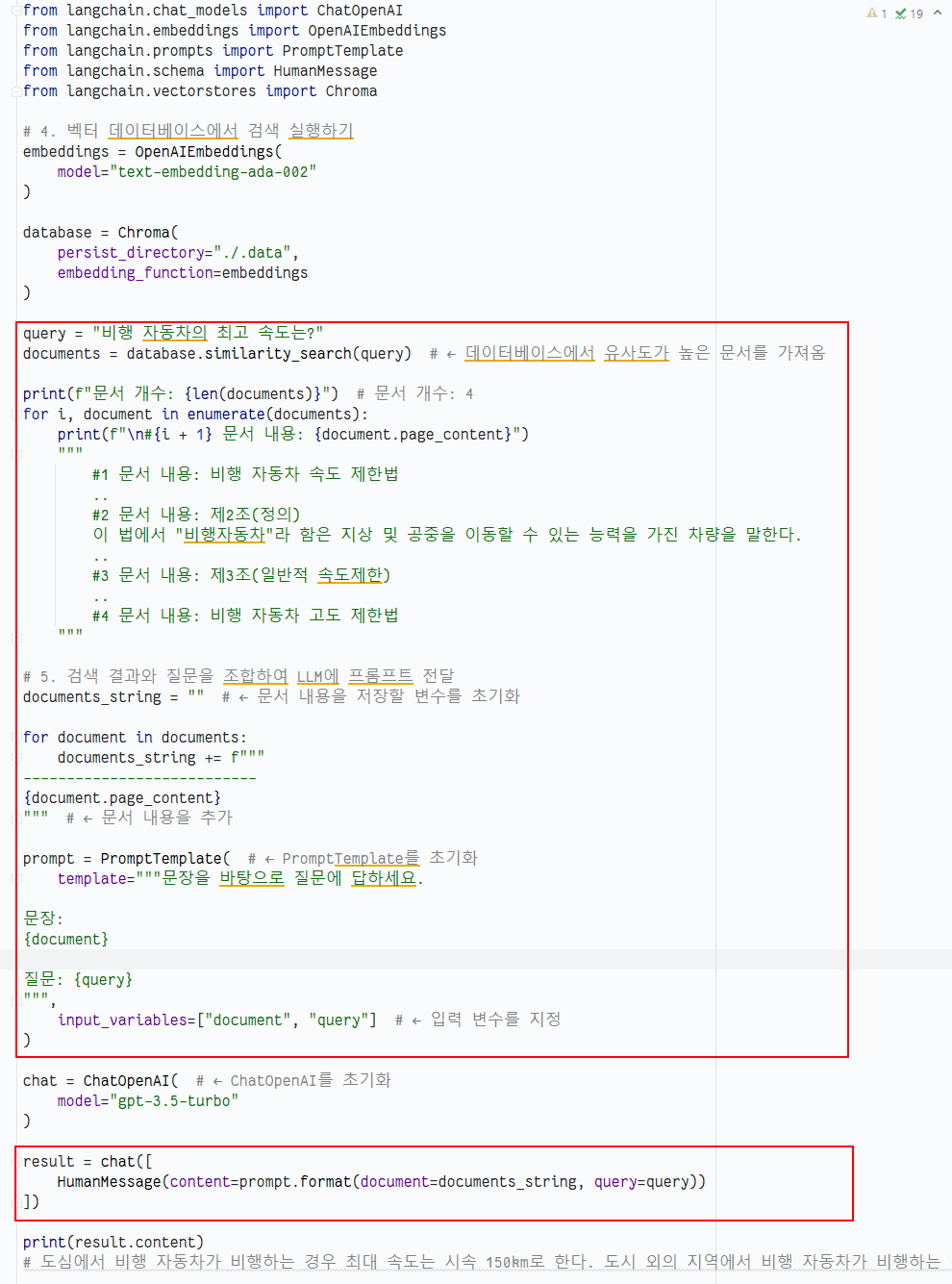
기존 query.py 코드에서 빨간색으로 표시된 부분이 RetrievalQA를 사용하며 아래 코드로 대체됨에 따라 코드의 양이 많이 준 것을 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
retriever = database.as_retriever() #← 데이터베이스를 Retriever로 변환
qa = RetrievalQA.from_llm( #← RetrievalQA를 초기화
llm=chat, #← Chat models를 지정
retriever=retriever, #← Retriever를 지정
return_source_documents=True #← 응답에 원본 문서를 포함할지를 지정
)
result = qa("비행 자동차의 최고 속도를 알려주세요")
RetrievalQA의 또 다른 장점
언어 모델을 호출할 때 입력되는 프롬프트의 구성은 다음과 같습니다.
- 질문
- 출처가 되는 문장
- 출처가 되는 문장을 바탕으로 질문에 답하도록 지시하는 문장
하지만 때때로 출처가 되는 문장이 너무 긴 경우, 프롬프트의 길이가 너무 길어져 언어 모델의 프롬프트 입력 문장 수 제한(콘텍스트 길이 제한)을 초과할 수 있습니다.
이러한 문제에 대응하기 위해 랭체인에서는 다음과 같은 결합방법을 제공합니다.
- Refine: 여러 단계에 걸쳐 답변을 개선합니다. 초기 답변을 바탕으로 추가 출처 문장을 사용해 답변을 점진적으로 수정합니다.
- 예: 첫 번째 답변을 바탕으로 두 번째 출처 문장을 추가하여 답변을 개선.
- Map Reduce: 각 출처 문장에 대해 개별적으로 답변을 생성한 후, 이 답변들을 종합하여 최종 답변을 만듭니다.
- 예: 여러 문장에서 각각 답변을 생성한 후, 이를 결합하여 최종 답변 도출.
- Map Re-rank: 각 출처 문장에 대해 답변을 생성하고, 그 답변들을 평가하여 가장 적합한 답변을 선택합니다.
- 예: 여러 문장에서 생성된 답변 중 가장 관련성이 높은 답변을 선택.
위와 같이 RetrievalQA에서는 정보 출처가 되는 문장의 조합 방법을 선택함으로써 다양한 태스크나 상황에 대응할 수도 있습니다.
✏️ Wrap up!
RetrievalQA를 적용해보니 일일이 코딩했던 것이 허무할 정도로 코드가 간단해지네요 :) ㅎㅎ 여유가 되실 때 전 챕터에서 만들었던 최종 코드에 RetrievalQA을 적용해보세요!
오늘 설명드린 기능 외에도 RetrievalQA은 정보원(출처)의 역할을 하기 때문에, RetrievalQA을 변경하므로써 다양한 출처를 변경해가는 RAG 어플리케이션을 구현하는 방법도 가능합니다! 해당 코드는 위키백과를 정보원으로 활용한 QA 서비스 코드인데요, retrievers 를 두 개를 체인으로 엮어 사용해서, 질문의 키워드를 뽑아 위키피디아에 검색한 출력을 주는 코드입니다. 관심이 있으신 분은 한번 살펴봐도 흥미로우실 거예요.
다음에는 정말 대화가 이루어지듯 이전 대화를 기억하고, 그 기억에 기반한 대답을 할 수 있는 랭체인의 Memory 모듈에 대해 공부해보겠습니다.