Langchain Study | 3-2. Retrieval3 - PDF기반-챗봇만들기-(실습)
지금까지 RAG의 개념과 Retrieval(검색기)를 통한 유사도 검색에 대한 개념에 대해 알아보았습니다.
이번 챕터에서는 랭체인의 Retrieval 모듈들을 이용하여, 어떻게 소스에 적용되고 활용하는지 같이 실제 예제를 통해 알아보겠습니다!
이번에 수행해볼 예제는 주어진 PDF 파일을 기반으로 답변하는 챗봇 만들기 입니다!
0. 사전 준비
라이브러리 다운로드
이번 실습을 수행하기 위해 추가적으로 설치해야 할 라이브러리입니다.
가상환경 활성화
1
.\{가상환경폴더명}\Scripts\activate
라이브러리 설치
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# PDF 문서 불러오는 모듈 pip install pymupdf==1.22.5 # Text Splitters 모듈 pip install spacy==3.6.1 # spaCy 한국어 처리 라이브러리 다운로드 python -m spacy download ko_core_news_sm # 임베딩 모델 pip install tiktoken==0.3.3 # 벡터 데이터 베이스 pip install chromadb==0.3.26 # 화면 라이브러리 pip install chainlit==0.5.1
개발 과정 개요
개발의 진행 순서는 아래의 과정으로 진행됩니다.
- PDF에서 문장 불러오기
- 문장 나누기
- 분할된 문장을 벡터화해 데이터 베이스 저장하기
- 벡터 데이터베이스에서 검색 실행하기
- 검색 결과와 질문을 조합하여 LLM에 프롬프트 전달
- 채팅 화면 만들기
- 채팅 화면에서 파일 업로드 기능 구현
- 업로드된 파일을 기반으로 답변 받기
- 1~3 과정은
사전준비: 벡터 데이터 베이스 구축과정에 속합니다. - 4~5 과정은
검색 및 프롬프트구축과정에 속합니다. - 6~8 과정은 프론트엔드를 구성하는 부분이며, 이번 실습에서는
chainlit이라는 라이브러리를 이용해보도록 하겠습니다. 그 외에도streamlit,Gradio등의 라이브러리를 통해 쉽게 프론트엔드를 구성할 수 있습니다. 이번 챕터에서의 주제는 랭체인이기 때문에chainlit의 사용법에 대한 자세한 설명은 생략하겠습니다.
어플리케이션 미리 보기
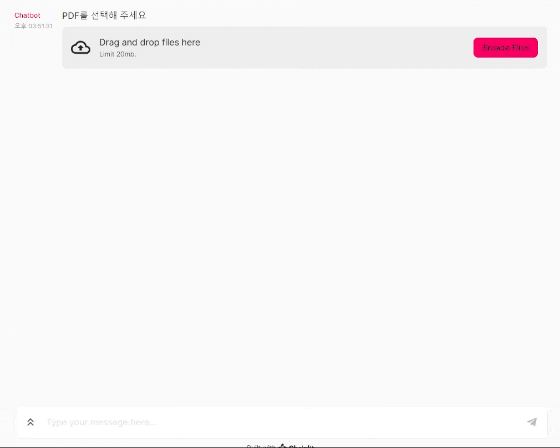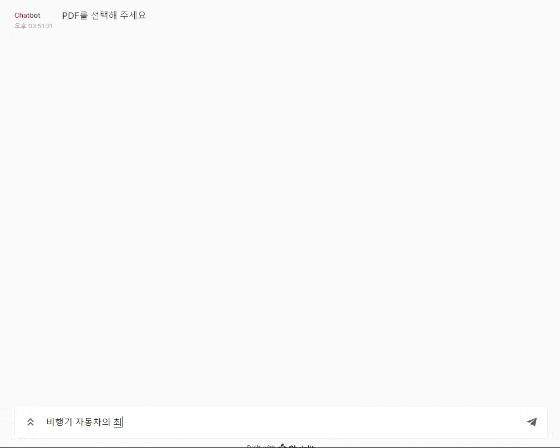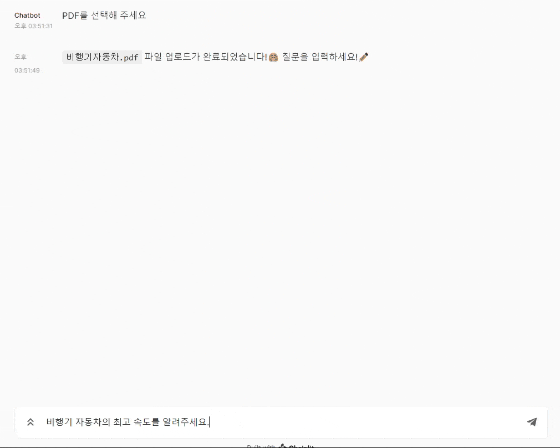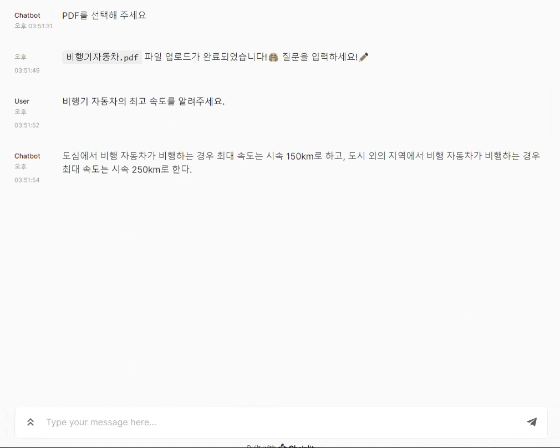
어플리케이션 아키텍쳐
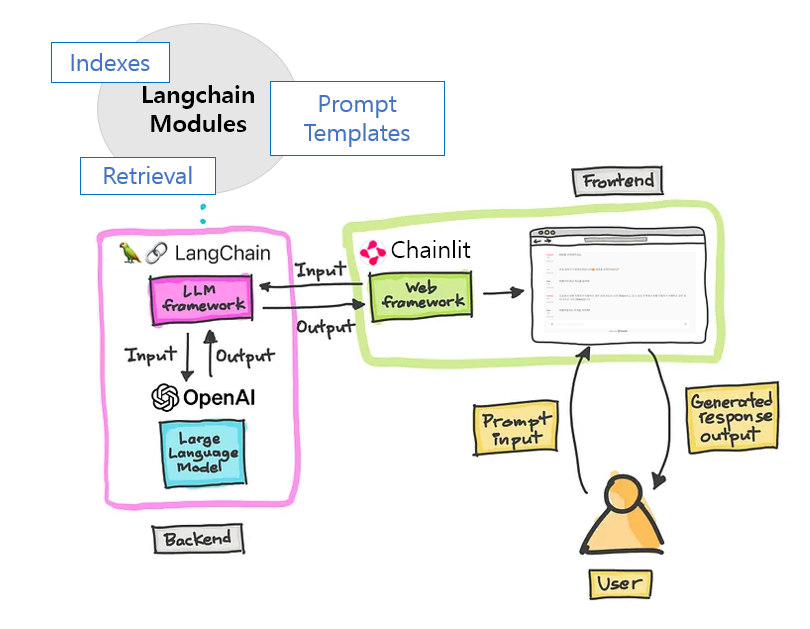
1. 사전준비: 벡터 데이터 베이스 구축
01_prepare.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from langchain.document_loaders import PyMuPDFLoader
from langchain.embeddings import OpenAIEmbeddings #← OpenAIEmbeddings 가져오기
from langchain.text_splitter import SpacyTextSplitter # ← SpacyTextSplitter를 가져옴
from langchain.vectorstores import Chroma #← Chroma 가져오기
# 1. PDF에서 문장 불러오기
loader = PyMuPDFLoader("./sample.pdf") # ← sample.pdf 로드
documents = loader.load()
print(f"문서 개수: {len(documents)}") #← 문서 개수 확인 (12개)
# 2. 문장 나누기
text_splitter = SpacyTextSplitter( # ← SpacyTextSplitter를 초기화
chunk_size=300, # ← 분할할 크기를 설정
pipeline="ko_core_news_sm" # ← 분할에 사용할 언어 모델을 설정
)
splitted_documents = text_splitter.split_documents(documents) # ← 문서를 분할
print(f"분할 후 문서 개수: {len(splitted_documents)}") # ← 문서 개수 확인 (70개)
# 3. 분할된 문장을 벡터화해 데이터 베이스 저장하기
embeddings = OpenAIEmbeddings( #← OpenAIEmbeddings를 초기화
model="text-embedding-ada-002" #← 모델명을 지정
)
database = Chroma( #← Chroma를 초기화
persist_directory="./.data", #← 영속화 데이터 저장 위치 지정
embedding_function=embeddings #← 벡터화할 모델을 지정
)
database.add_documents( #← 문서를 데이터베이스에 추가
splitted_documents, #← 추가할 문서 지정
)
print("데이터베이스 생성이 완료되었습니다.")
먼저 첫 번째 단계인 PDF를 로드하여, 문장을 불러온다.
sample.pdf라는 PDF 파일을 PyMuPDFLoader를 통해 읽어옵니다. load() 메서드를 통해 PDF 파일로부터 정보를 불러오고, Document 클래스 객체의 배열로 반환됩니다. 1 페이지 마다 1개의 Document 객체로 생성하기 때문에 총 12개의 Document가 있는 배열을 반환합니다. 각 Document는 page_content와 metadata로 구성됩니다. page_content는 문서의 원본 내용, metadata는 어떤 문서인지 저장하기 위한 메타정보가 담겨있습니다.
두 번째로 문장나누기를 수행한다.
PDF에서 가져온 문장을 통째로 처리하는 것은 RAG 기법으로 효율적이기 않기 때문에, 문맥을 유지하면서 적절한 청크로 문장을 분할합니다. 랭체인에서는 여러가지의 Text Splitters 모듈이 존재하고, 이번 예제에서는 spaCy를 사용합니다. chunk_size 매개변수를 사용해 문장을 분할할 크기를 지정하고, pipline에서는 분할에 사용할 spaCy 언어 모델을 지정합니다.
이를 통해 RAG기법으로 다루기 쉬운 크기의 문장으로 분할할 수 있습니다.
세 번째로 분할된 문장을 벡터화해 벡터 데이터베이스에 저장한다.
OpenAIEmbeddings을 통해 지정한 모델명으로 임베딩 모델을 지정합니다. 벡터 데이터베이스로는 Chroma(크로마)를 사용합니다. persist_directory에서 경로를 설정하면 임베딩된 데이터를 벡터 저장소에 영속적으로 저장할 경로를 생성합니다. 이는 파이썬 명령의 실행이 종료되더라도 데이터베이스의 내용이 삭제되지 않아 영속적으로 사용할 수 있습니다. embedding_function에는 위에서 선언한 벡터 임베딩 모델을 지정한다. add_documents()를 통해 분할된 Document를 벡터화해 데이터베이스에 저장합니다.
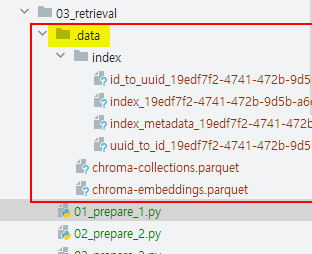
임베딩이 완료되면 지정한 경로에 임베딩된 데이터베이스가 파일로 저장됩니다. 만약 기존 임베딩된 데이터를 지우고, 새롭게 임베딩을 수행하여 벡터DB에 저장을 원한다면 .data 폴더를 지우고 재수행하면 됩니다.
이를 통해 랭체인을 사용해 PDF에서 문장을 읽고, 문장을 적절한 크기로 분할하고, 그 문장을 벡터화하여 저장소에 저장하기까지의 작업을 완료했습니다.
2. 검색 및 프롬프트 구축
위 코드를 통해 외부 데이터를 벡터 데이터베이스로 구축 한 후, 입력된 쿼리를 통한 검색을 실행해 실제로 유사한 문장을 검색해봅시다.
02_query.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
# 4. 벡터 데이터베이스에서 검색 실행하기
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings
)
query = "비행 자동차의 최고 속도는?"
documents = database.similarity_search(query) # ← 데이터베이스에서 유사도가 높은 문서를 가져옴
print(f"문서 개수: {len(documents)}") # 문서 개수: 4
for i, document in enumerate(documents):
print(f"\n#{i + 1} 문서 내용: {document.page_content}")
"""
#1 문서 내용: 비행 자동차 속도 제한법
..
#2 문서 내용: 제2조(정의)
이 법에서 "비행자동차"라 함은 지상 및 공중을 이동할 수 있는 능력을 가진 차량을 말한다.
..
#3 문서 내용: 제3조(일반적 속도제한)
..
#4 문서 내용: 비행 자동차 고도 제한법
"""
# 5. 검색 결과와 질문을 조합하여 LLM에 프롬프트 전달
documents_string = "" # ← 문서 내용을 저장할 변수를 초기화
for document in documents:
documents_string += f"""
---------------------------
{document.page_content}
""" # ← 문서 내용을 추가
prompt = PromptTemplate( # ← PromptTemplate를 초기화
template="""문장을 바탕으로 질문에 답하세요.
주어진 문장과 관련이 없는 질문인 경우, "주어진 문서로는 알 수 없는 정보입니다. PDF와 관련된 질문을 해주세요."라고 답변해주세요.
문장:
{document}
질문: {query}
""",
input_variables=["document", "query"] # ← 입력 변수를 지정
)
chat = ChatOpenAI( # ← ChatOpenAI를 초기화
model="gpt-3.5-turbo",
max_tokens=2048,
temperature=0.1,
)
result = chat([
HumanMessage(content=prompt.format(document=documents_string, query=query))
])
print(result.content)
# 도심에서 비행 자동차가 비행하는 경우 최대 속도는 시속 150km로 한다. 도시 외의 지역에서 비행 자동차가 비행하는 경우 최대 속도는 시속 250km로 한다.
네 번째 단계인 벡터 데이터베이스에서 검색을 실행한다.
이는 입력받은 질문을 가지고 이와 관련된 문서(질문과 유사한 문장)를 벡터 데이터베이스에서 반환받는 과정입니다. embedding과 database는 위 코드에서 지정한 정보와 동일합니다. 현 시점에서는 벡터 데이터베이스를 구축하기 위함이 아닌, 기존 존재하는 데이터베이스를 호출하여 검색 대상으로 지정하기 위해 정의합니다. similarity_search 를 통해 질의문과 유사한 문장을 검색하고, 질의문과 벡터가 비슷한 Document 목록을 반환합니다. 총 4개의 문서가 반환되었으며, 내용은 비행기 최고 속도와 관련이 있는 문서들이 반환된 것으로 확인됩니다.
다섯 번째 단계에서는 검색 결과와 질문을 조합하여 LLM에게 전달하여 질문에 답하게 한다.
검색결과와 질문을 조합하여 프롬프트를 작성하고, 언어 모델을 호출합니다. documents_string에 document.page_content을 통해 반환받은 Document의 문서 내용만을 반복문을 통해 하나의 문자열로 할당합니다. PromptTemplate을 사용해 프롬프트를 생성하기 위한 템플릿을 구성합니다. document에는 정보원인 document_string을, query에는 질문을 조합하여 프롬프트를 생성하고, ChatOpenAI에서 언어 모델과 채팅을 진행합니다.
:bulb:[참고]
ChatOpenAI의 옵션
temperature: 사용할 샘플링 온도는 0과 2 사이에서 선택합니다. 0.8과 같은 높은 값은 출력을 더 무작위하게 만들고, 0.2와 같은 낮은 값은 출력을 더 집중되고 결정론적으로 만듭니다.max_tokens: 채팅 완성에서 생성할 토큰의 최대 개수입니다.
여기까지 과정을 통해 Retrieval의 각 모듈을 사용해 PDF에서 문장을 읽고, 적절한 청크로 분할하여 청크를 벡터화하여 벡터 저장소에 저장하고, 질문을 입력받아 벡터 데이터베이스를 사용해 질문에 답변하는 애플리케이션을 구성하였습니다.
3. 프론트엔트 구축
이제 지금까지 개발한 AI 어플리케이션을 실제로 브라우저에서 수행할 수 있는 채팅 화면을 개발해봅시다. 이 예제에서는 chainlit이라는 라이브러리를 사용합니다.
:bulb:chainlit은 랭체인과는 별개의 라이브러리입니다! 하지만 결합하면 채팅화면에서 쉽게 랭체인을 사용할 수 있습니다.
:exclamation:️️지금까지 작성한 코드는 sample.pdf라는 pdf 파일을 지정 후 RAG 기법을 구현하였으나, 이번에는 브라우저에서 사용자로부터 PDF 파일을 업로드받아 해당 PDF로 벡터 데이터베이스를 구성하는 방법으로 진행해봅시다.
03_chat.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
import os
import chainlit as cl
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import SpacyTextSplitter
# 임베딩 모델 초기화
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# LLM 모델 초기화
chat = ChatOpenAI( # ← ChatOpenAI를 초기화
model="gpt-3.5-turbo",
max_tokens=2048,
temperature=0.1,
)
# 프롬프트 생성
prompt = PromptTemplate(
template="""문장을 바탕으로 질문에 답하세요.
만약 주어진 문장과 관련없는 질문이라면 "주어진 문서로는 알 수 없는 정보입니다. PDF와 관련된 질문을 해주세요."라고 답변해주세요.
문장:
{document}
질문: {query}
""",
input_variables=["document", "query"]
)
# 문서 분할
text_splitter = SpacyTextSplitter(
chunk_size=300,
pipeline="ko_core_news_sm"
)
# 7. 채팅 화면 만들기
@cl.on_chat_start # ← 채팅이 시작될 때 실행할 함수를 정의
async def on_chat_start():
# 8. 채팅 시작 시 파일 업로드 기능 구현
files = None #← 파일이 선택되어 있는지 확인하는 변수
while files is None: #← 파일이 선택될 때까지 반복
files = await cl.AskFileMessage(
max_size_mb=20,
content="PDF를 선택해 주세요",
accept=["application/pdf"],
raise_on_timeout=False,
).send()
file = files[0]
if not os.path.exists("tmp"): #← tmp 디렉터리가 존재하는지 확인
os.mkdir("tmp") #← 존재하지 않으면 생성
with open(f"tmp/{file.name}", "wb") as f: #← PDF 파일을 저장
f.write(file.content) #← 파일 내용을 작성
# 1. PDF에서 문장 불러오기
documents = PyMuPDFLoader(f"tmp/{file.name}").load() #← 저장한 PDF 파일을 로드
# 2. 문장 나누기
splitted_documents = text_splitter.split_documents(documents) #← 문서를 분할
# 3. 분할된 문장을 벡터화해 데이터 베이스 저장하기
database = Chroma( #← 데이터베이스 초기화
embedding_function=embeddings,
# 이번에는 persist_directory를 지정하지 않음으로써 데이터베이스 영속화를 하지 않음
)
database.add_documents(splitted_documents)
cl.user_session.set( #← 데이터베이스를 세션에 저장
"database", #← 세션에 저장할 이름
database #← 세션에 저장할 값
)
await cl.Message(content=f"`{file.name}` 파일 업로드가 완료되었습니다!🤗 질문을 입력하세요!✏️").send()
# 9. 업로드된 파일을 기반으로 답변 받기
@cl.on_message # ← 메시지를 보낼 때 실행할 함수를 정의
async def on_message(input_message):
# 4. 채팅 화면에서 질문을 입력받기
print("입력된 메시지: " + input_message)
# 5. 기존 임베딩된 벡터DB에 유사도 검색을 통해 질문과 연관된 관련 문서 받아오기
database = cl.user_session.get("database") #← 세션에서 데이터베이스를 가져옴
documents = database.similarity_search(input_message) # ← 입력받은 질문으로 데이터베이스에서 유사도가 높은 문서를 가져옴
# 관련 문서를 문서 내용만 추출하여 하나의 문자열로 정의
document_string = '---------------\n'.join([doc.page_content for doc in documents]) if len(documents) > 0 else ''
# 6. LLM에 벡터 저장소에서 검색한 관련 문서와 채팅으로 입력받은 질문 반환
result = chat([
HumanMessage(content=prompt.format(document=document_string, query=input_message))
])
await cl.Message(content=result.content).send() # ← 챗봇의 답변을 보냄
03_chat.py는 위에서 작업한 사전준비: 벡터 데이터 베이스 구축과 검색 및 프롬프트 구축작업을 포함하였다. 위에서 이미 설명한 과정에 대한 자세한 설명은 생략합니다.
chainlit의 수행을 위해서는 python 명령어가 아닌, chainlit 명령어로 수행할 수 있습니다.
1
chainlit run 03_chat.py
run은 서버 시작을 의미하며, 위 명령어를 수행하면 http://localhost:8080이 열리고 브라우저에 채팅창 어플리케이션이 로컬에서 수행됩니다.
여섯번 째 과정인 채팅 화면을 만들어보자.
@cl.on_chat_start라는 데코레이터가 붙은 함수는 새로운 채팅이 시작될 때 마다 실행된다. 일반적으로 처음에 표시하고 싶은 메시지나 실행하고 싶은 처리를 정의합니다. cl.Message는 메시지를 채팅창에 표시하는 처리입니다. @cl.on_message라는 데코레이터가 붙은 함수는 사용자가 메시지를 보낼 때마다 실행됩니다.
이를통해 기본적인 채팅 화면은 구현됩니다.
일곱번 째로 채팅 화면에서 파일 업로드 기능 구현해보자.
chainlit에서는 cl.AskFileMessage를 실행해 파일을 업로드 받는 컴퍼넌트를 구성할 수 있습니다. PDF 파일을 업로드받은 후, 로컬에 저장하여 PyMuPDFLoader을 통해 해당 파일을 불러와서 텍스트를 추출합니다. SpacyTextSplitter를 통해 텍스트를 분할합니다. 벡터 데이터베이스에 저장한 후에 이번에는 굳이 영속화할 필요가 없습니다. 프로그램이 종료되기 전에 업로드된 데이터로 질의응답을 수행하기 때문입니다. 다만 질문이 입력되었을 때, 벡터 데이터베이스에 저장되어 있는 PDF 파일을 기반으로 답변을 생성해야 하기 때문에 cl.user_session.set을 통해 데이터베이스를 세션에 저장합니다.
마지막으로 업로드된 파일을 기반으로 답변 받는 과정까지 구현해봅시다.
파일 업로드가 완료된 후, 브라우저로부터 사용자에게 질문을 받습니다. 기존 세션에 저장해 둔 벡터 데이터베이스로부터 입력받은 질문을 similarity_search을 통해 유사도 검색을 수행합니다. 그 후 PromptTemplate을 통해 document에는 관련 문서를, query에는 사용자로부터 입력받은 질문을 하나의 프롬프트로 생성하여 LLM에 전달합니다. LLM으로부터 받은 답변을 브라우저에 출력합니다.
:pencil2:️️️ Wrap up!
이번 챕터에서는 랭체인의 Retrieval 모듈들과 chainlit을 이용하여 LLM 어플리케이션 개발을 진행해보았습니다! 지금까지 배운 개념들을 실제로 코드로 옮겨서 진행하는 과정을 해보았는데요, 이제 개념들이 조금 더 와닿으실 수 있는 시간이 되었으면 좋겠습니다 :) .
다음 챕터에서는 RAG 기법을 이용한 QA 시스템을 보다 쉽게 개발할 수 있는 RetrievalQA 모듈을 소개해드리겠습니다!.
Python 3.12 환경
- version 호환성에 따른 library 변경
- api 변경에 따른 코드 변경
- local에 저장하던 코드 삭제 : 임시로 파일이 저장되어 해당 파일을 바로 load 할 수 있음.
- on_message(input_message) 의 input_message.content 사용으로 변경
- gpt-4o가 더 좋은 답변을 함.
chat.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
import os
import chainlit as cl
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import SpacyTextSplitter
# 임베딩 모델 초기화
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# LLM 모델 초기화
chat = ChatOpenAI( # ← ChatOpenAI를 초기화
model="gpt-4o",
max_tokens=2048,
temperature=0.1,
)
# 프롬프트 생성
prompt = PromptTemplate(
template="""문장을 바탕으로 질문에 답하세요.
만약 주어진 문장이 없다면, "주어진 문서로는 알 수 없는 정보입니다. PDF와 관련된 질문을 해주세요."라고 답변해주세요.
문장:
{document}
질문: {query}
""",
input_variables=["document", "query"]
)
# 문서 분할
text_splitter = SpacyTextSplitter(
chunk_size=300,
pipeline="ko_core_news_sm"
)
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings
)
# 7. 채팅 화면 만들기
@cl.on_chat_start # ← 채팅이 시작될 때 실행할 함수를 정의
async def on_chat_start():
# 8. 채팅 시작 시 파일 업로드 기능 구현
files = None #← 파일이 선택되어 있는지 확인하는 변수
while files is None: #← 파일이 선택될 때까지 반복
files = await cl.AskFileMessage(
max_size_mb=20,
content="PDF를 선택해 주세요",
accept=["application/pdf"],
raise_on_timeout=False,
).send()
file = files[0]
# 1. PDF에서 문장 불러오기
documents = PyMuPDFLoader(file.path).load() #← 저장한 PDF 파일을 로드
# 2. 문장 나누기
splitted_documents = text_splitter.split_documents(documents) #← 문서를 분할
# 3. 분할된 문장을 벡터화해 데이터 베이스 저장하기
database = Chroma( #← 데이터베이스 초기화
embedding_function=embeddings,
# 이번에는 persist_directory를 지정하지 않음으로써 데이터베이스 영속화를 하지 않음
)
database.add_documents(splitted_documents)
cl.user_session.set( #← 데이터베이스를 세션에 저장
"database", #← 세션에 저장할 이름
database #← 세션에 저장할 값
)
await cl.Message(content=f"`{file.name}` 파일 업로드가 완료되었습니다!🤗 질문을 입력하세요!✏️").send()
# 9. 업로드된 파일을 기반으로 답변 받기
@cl.on_message # ← 메시지를 보낼 때 실행할 함수를 정의
async def on_message(input_message):
# 4. 채팅 화면에서 질문을 입력받기
print("입력된 메시지: {}".format(input_message.content) )
# 5. 기존 임베딩된 벡터DB에 유사도 검색을 통해 질문과 연관된 관련 문서 받아오기
database = cl.user_session.get("database") #← 세션에서 데이터베이스를 가져옴
documents = database.similarity_search(input_message.content) # ← 입력받은 질문으로 데이터베이스에서 유사도가 높은 문서를 가져옴
# 관련 문서를 문서 내용만 추출하여 하나의 문자열로 정의
documents_string = ""
for document in documents:
documents_string += f"""
---------------------------
{document.page_content}
"""
# 6. LLM에 벡터 저장소에서 검색한 관련 문서와 채팅으로 입력받은 질문 반환
result = chat([
HumanMessage(content=prompt.format(document=documents_string, query=input_message.content))
])
await cl.Message(content=result.content).send() # ← 챗봇의 답변을 보냄