Langchain Study | 3-2. Retrieval2 - Vector Store
이전 챕터의 RAG 아키텍쳐에 대해 살펴보면서 임베딩과 벡터 저장소(벡터 데이터베이스)에 대한 용어를 간단하게 짚고 넘어갔었습니다!
이번 챕터에서는 데이터 소스가 벡터 데이터베이스에 저장이 되고, 사용자가 입력한 질문으로 벡터 데이터베이스에서 관련 정보를 추출하는 과정이 어떻게 진행되는 지에 대해 알아보도록 하겠습니다.
각 과정에서 어떤 Langchain의 모듈들이 사용되는지도 함께 알아봅시다!
벡터 임베딩
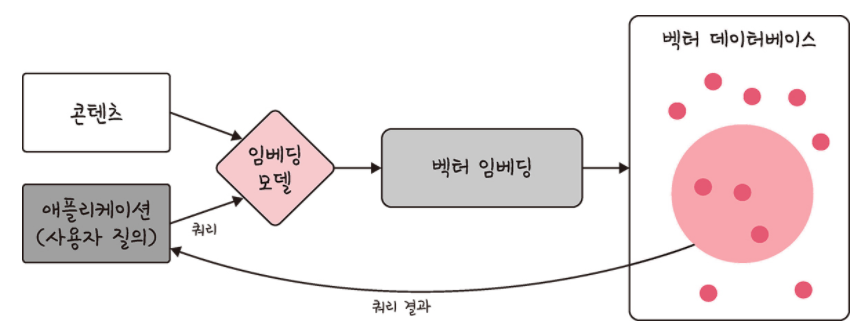
RAG 구조에서의 벡터 임베딩은 크게 두 번으로 구분할 수 있습니다.
벡터 데이터베이스를 구축하기 위한 데이터 소스를 벡터 임베딩
어플리케이션으로부터 입력된 사용자의 질문(쿼리)를 벡터 임베딩
벡터 임베딩 이후에 벡터 임베딩된 쿼리를 벡터 데이터베이스에서 유사도 검색(semantic search-의미적 유사성 검색)을 통해 관련 문서를 반환하는 것까지 이루어집니다.
앞 챕터에서 임베딩과 벡터화에 대해 아래의 개념으로 간단하게 익혔습니다.
임베딩? 벡터화의 일종으로, 텍스트 데이터를 컴퓨터가 이해할 수 있는 벡터로 변환하여 의미론적 정보를 유지하는 과정 => 단어 간 유사성을 반영
벡터화? 텍스트 데이터를 숫자 벡터로 변환하는 일반적인 과정
유사도 검색(semantic search)
그렇다면 벡터 데이터베이스에서 어떻게 유사성 검색이 이루어지는 걸까요?
예를 들어, “고양이”와 “강아지”와 “사과” 라는 단어를 벡터화한다고 합시다. 이 단어들을 각각 3차원 벡터로 표현하면, “고양이”는 [0.7, 0.2, 0.1]와 같이, “강아지”는 [0.6, 0.3, 0.2], “사과”는 [0.1, 0.8, 0.9] 같은 벡터로 변환될 수 있습니다.
| 동물 | 빨간색 | 채소 | |
|---|---|---|---|
| 고양이 | 0.7 | 0.2 | 0.1 |
| 강아지 | 0.6 | 0.3 | 0.2 |
| 사과 | 0.1 | 0.8 | 0.9 |
이러한 벡터는 단어의 의미를 반영하여, 비슷한 의미의 단어들은 유사한 벡터 값을 가지게 됩니다.
벡터 데이터베이스에서 유사성 검색이 이루어지는 방식도 비슷합니다. 예를 들어, “고양이는 어떻게 키우나요?”라는 사용자의 질문을 벡터화하여 [0.8, 0.1, 0.1]이라는 벡터로 변환했다고 가정합시다. 이 벡터를 벡터 데이터베이스에 저장된 수많은 문서의 벡터와 비교하여 가장 유사한 벡터를 찾는 것이 유사성 검색입니다.
유사성 검색은 보통 코사인 유사도(cosine similarity)라는 방법을 사용합니다. 코사인 유사도는 두 벡터 사이의 각도를 계산하여, 각도가 작을수록(즉, 벡터가 비슷할수록) 유사성이 높다고 판단합니다.
예를 들어, 데이터베이스에 저장된 문서 중 하나의 벡터가 [0.75, 0.2, 0.05]라면, 이 벡터와 사용자의 질문 벡터 [0.8, 0.1, 0.1]의 코사인 유사도를 계산하여 두 벡터가 얼마나 유사한지 판단할 수 있습니다. 만약 이 유사도가 높다면, 해당 문서는 사용자의 질문과 관련이 높다고 판단하여 반환합니다.
이런 과정을 통해 사용자의 질문에 가장 관련 있는 문서를 찾아낼 수 있게 됩니다. 이는 마치 도서관에서 키워드를 검색하여 관련 책을 찾아내는 것과 비슷한 원리입니다.
RAG 아키텍쳐에서의 벡터 유사도 검색
지난 챕터에서 보았던 RAG 아키텍쳐에서 벡터 임베딩과 벡터 유사도 검색이 적용되는 부분은 노란색과 하늘색 부분으로 표시해보았습니다.
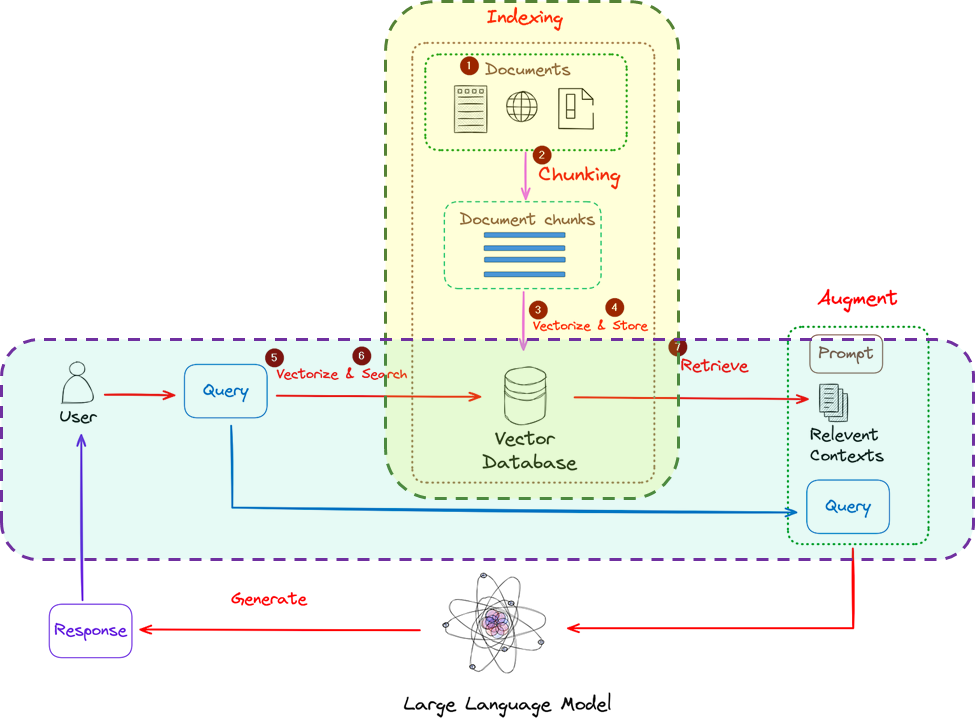
RAG 아키텍쳐에서 벡터 임베딩과 유사도 검색이 적용되는 부분은 크게 두 부분으로 구분됩니다.
사전준비: 벡터 데이터 베이스 구축
먼저 노란색 부분인 벡터 데이터베이스를 구축하는 부분을 살펴봅시다.
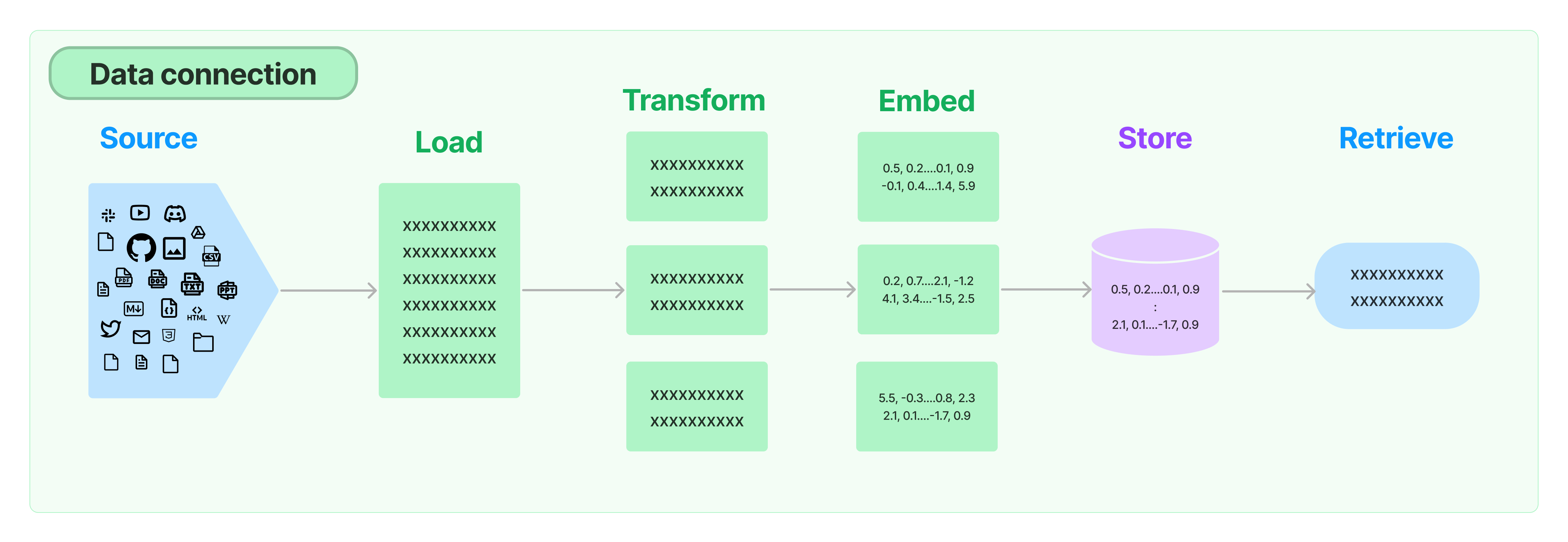
Load텍스트 추출원본 데이터를 로딩해오는 과정입니다.
텍스트가 아닌 형태인 경우 랭체인 모듈을 사용하여, PDF, 엑셀 등의 파일을 텍스트 형태로 변환할 수 있습니다.
사용 모듈:
Document Loaders
Transform텍스트 분할임베딩되기 위한 글의 단위를 길이와 의미를 고려하여 분할합니다.
이렇게 나눠진 단위(덩어리)를 청크라고 표현하기도 합니다.
사용 모듈:
Text Splitters
Embed텍스트 벡터화텍스트를 벡터로 임베딩합니다. 벡터 데이터베이스에서 가장 유사한 청크를 찾는 유사도 검색(의미론적 검색)과 같은 작업을 수행할 수 있도록 해줍니다.
랭체인에서는 문서를 임베딩하는 메서드와 쿼리를 임베딩하는 메서드가 구분되어 제공됩니다. 따로 제공하는 이유는 일부 임베딩 제공자가 문서(검색 대상)에 대한 임베딩과 쿼리(검색 쿼리 자체)에 대한 임베딩을 다르게 처리하기 때문입니다.
임베딩을 처리해주는 모델의 종류는 다양합니다. OpenAI, Cohere, Hugging Face 등 다양한 임베딩 모델이 있습니다.
사용 모듈:
Text embedding models
Store텍스트와 벡터를 벡터 스토어에 저장- 벡터 저장소는 벡터화한 숫자 배열을 저장하는 데 특화한 데이터 베이스
- 여러 종류 있음
- 사용 모듈:
Vector stores
검색 및 프롬프트구축
외부 데이터 소스로 벡터 데이터베이스를 구축한 후, 이를 통해 질문에 대한 답변을 생성하는 부분인 파란색 부분에 대해 알아봅시다.
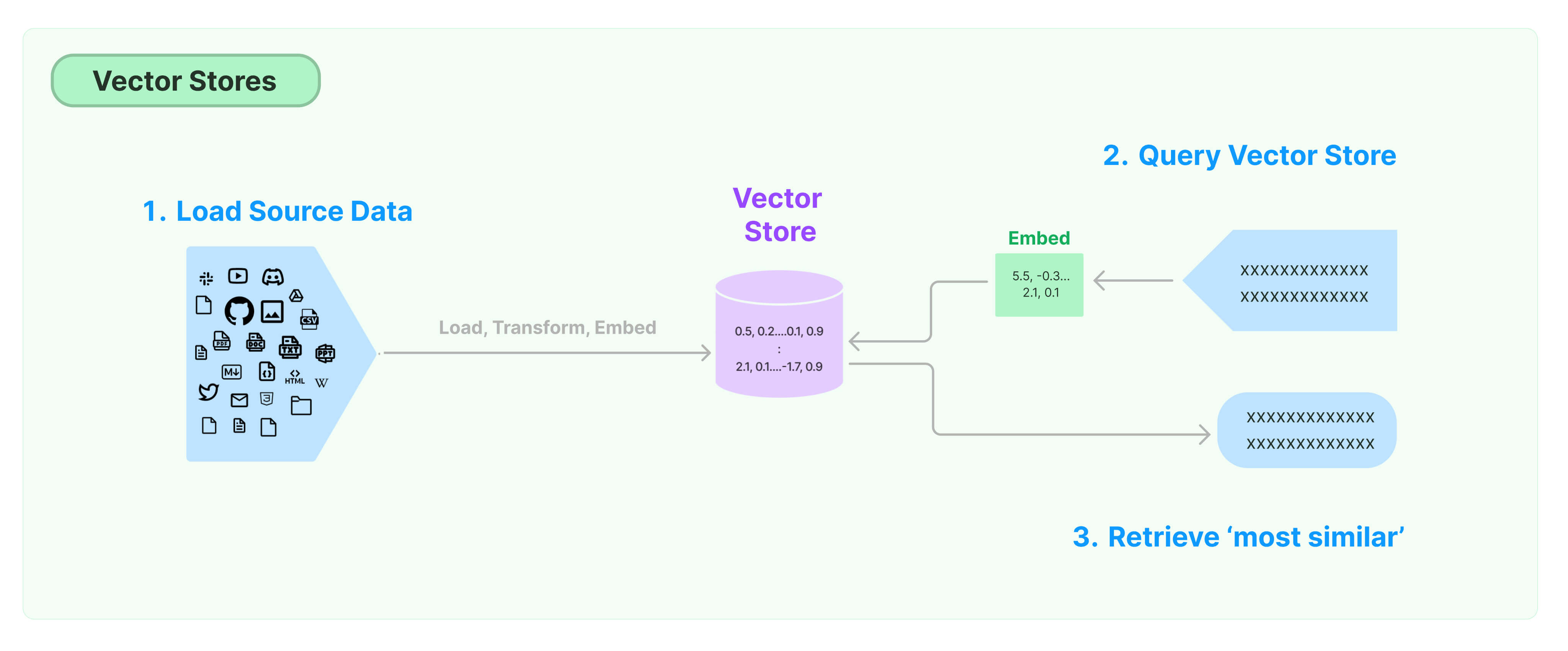
Query Vector Store사용자 입력(질문)을 벡터화- 벡터 데이터베이스에 저장된 정보와 가장 유사한 데이터를 검색하기 위해 질문을 벡터화
- 사용 모듈:
Text embedding models
사용자 입력의 벡터를 미리 준비된 데이터베이스에서 유사도 검색을 통해 문장 가져오기
획득한 유사 문장과 질문 조합한 프롬프트 작성
- 사용 모듈: model I/O의
PromptTemplate을 사용해 유사 문장과 질문을 조합
- 사용 모듈: model I/O의
언어모델 호출
- 사용 모듈: model I/O의
Language Model을 사용해 생성한 프롬프트를 기반으로 호출
- 사용 모듈: model I/O의
✏️ Wrap up!
이번 챕터에서는 RAG 구조에서 벡터 임베딩이 적용되는 부분과 그 절차에 대해 알아보았습니다.
랭체인에서 구현할 때 사용되는 모듈이 어떤 모듈인지에 대해서 살짝 알아보았는데요, 다음 챕터에서는 이제 이러한 모듈들을 소스 코드에 적용해서 간단한 RAG 어플리케이션을 개발해보도록 하겠습니다!