Langchain Study | 3-2. Retrieval1 - RAG
RAG란 무엇이고, 왜 필요할까?
GPT와 같은 언어모델(LLM)은 기존에 학습된 정보를 바탕으로 답변을 생성합니다. 그렇기 때문에 모델 학습 이후의 최신 정보나, 공개되지 않은 기업 고유의 매뉴얼 등 사용자 특정 데이터에 대한 답변을 하지 못합니다.
이 문제를 해결하는 방법 중 하나가 바로 RAG(Retrieval-Augumented Generation) 입니다! 직역하면 검색증강생성? 인데요. LLM을 통해 답변을 생성할 때, 검색의 대상의 수나 양을 더 늘려서 보강한다! 라는 의미로 이해할 수 있을 것 같습니다.
간단히 말해
RAG란 언어 모델이 모르는 정보에 대해 대답하게 하는 기법입니다.
RAG의 작동 방식
기존 LLM에 질문을 던지고 답변을 받는 방법과 RAG 방식을 사용하여 LLM에 질문을 던지고 답변을 받는 방법의 차이는 다음과 같습니다.
- 단순 LLM을 이용한 LLM 질문/답변 흐름
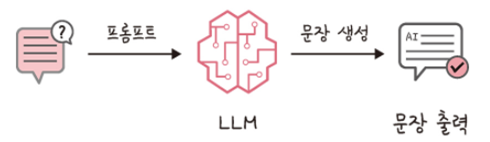
- RAG 방식을 사용한 LLM 질문/답변 흐름
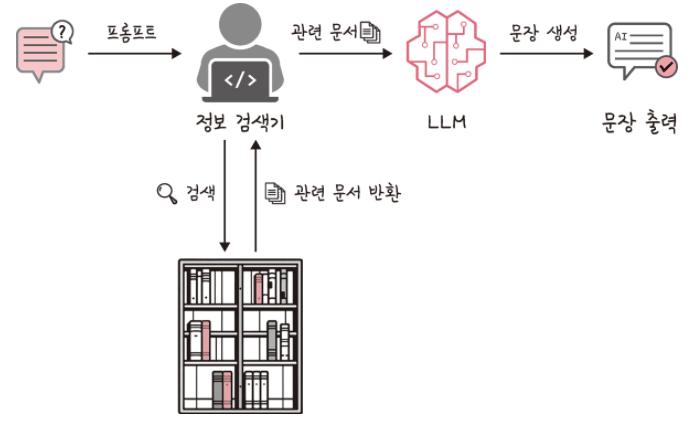
두 과정의 차이를 보면 RAG 방식의 경우 LLM에 바로 프롬프트를 던지지 않고, 정보 검색기 를 통해 새로 프롬프트를 생성하여 LLM에 질문을 던집니다.
정보 검색기에 의해 생성된 프롬프트는 아래의 두 개의 합으로 구성됩니다.
질문자가 입력한 질문
입력된 질문을 통해, 추가 데이터가 있는 저장소에서 질문과 관련있는 정보를 추출
예를 들어 회사 점심 메뉴를 알려주는 어플리케이션이라고 생각해봅시다. 추가 데이터 저장소에는 매달 회사에서 제공되는 점심메뉴의 메뉴리스트가 저장되어 있습니다. 제가 어플리케이션에 “오늘 점심 메뉴 알려줘” 라는 질문을 하면, 정보 검색기에 의해 오늘의 점심 메뉴에 관련된 문서를 반환받습니다. 관련 문서의 내용이 “2024/5/31 메뉴: 김치찌개, 쌀밥, 계란말이, 불고기, 김치” 입니다. 그렇다면 이제 LLM에 제가 입력한 질문과 반환받은 관련문서의 정보를 함께 프롬프트로 입력됩니다.
1
2
3
4
5
정보를 바탕으로 질문에 답해주세요.
정보: 2024/5/31 메뉴: 김치찌개, 쌀밥, 계란말이, 불고기, 김치
질문: 오늘 점심 메뉴 알려줘
해당 프롬프트를 입력받은 LLM은 추가적인 데이터를 기반으로 답변을 생성해줍니다.
RAG를 활용한 어플리케이션에서는 질문을 받으면 다음의 절차를 진행합니다.
사용자에게 질문 받기 => “오늘 점심 메뉴 알려줘”
준비된 문장에서 답변에 필요한 부분 찾기 => 2024/5/31 메뉴
문장의 관련 부분과 사용자 질문을 조합해 프롬프르 생성하기
생성한 프롬프트로 언어 모델을 호출해 사용자에게 결과 반환하기
그렇다면 RAG의 검색기에서 어떻게 답변에 필요한 문장을 검색하고 가져오는 것일까요?
이는 유사도 검색 방법을 이용합니다. 질문(프롬프트)와 유사한 정보를 데이터 소스(외부 데이터)에서 찾아서 반환하는 것입니다. 하지만 사람과 달리 컴퓨터는 직관적으로 유사한 문장을 찾아내지 못합니다. 그렇기 때문에 질문과 데이터 소스를 숫자로 변환하는 임베딩 과정을 거쳐, 벡터 저장소에 저장 후에 유사도 검색을 수행하여 관련 정보를 색출합니다. 데이터 임베딩과 벡터 저장소에 대한 설명은 다음 챕터에서 자세히 다루도록 하겠습니다. 이번 챕터에서는 그러한 과정으로 수행된다 까지만 이해하고 넘어가셔도 좋습니다!
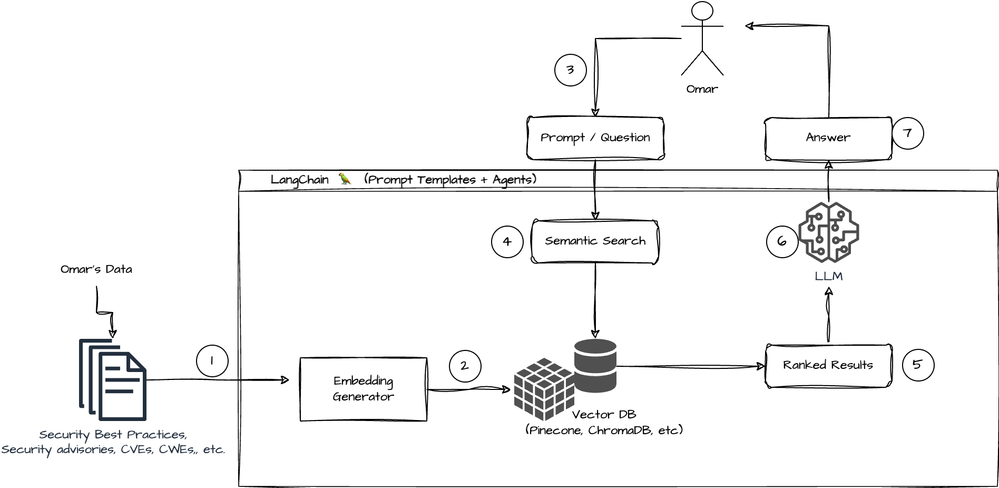
RAG 아키텍쳐
RAG가 수행되는 아키텍쳐를 설명한 그림 두 장입니다.
두 개의 그림을 같이 보면서 흐름을 파악해봅시다.
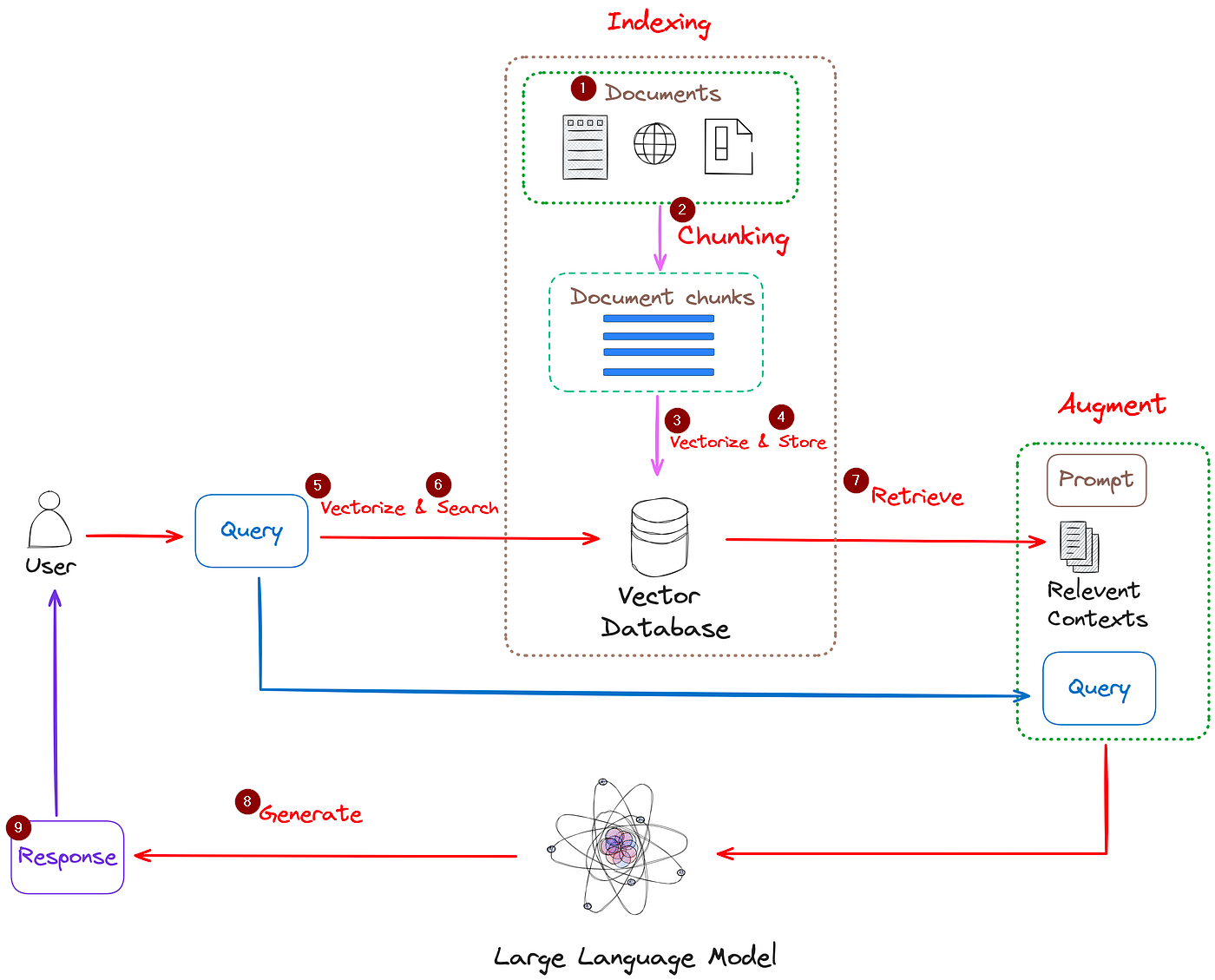
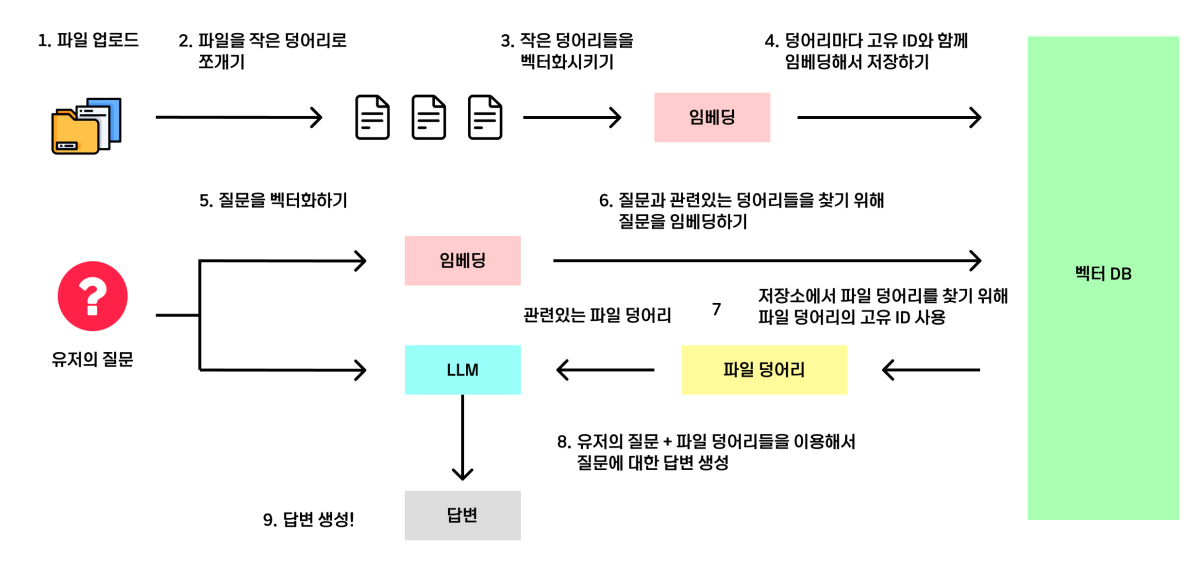
외부 데이터(데이터의 형식은 텍스트 파일 뿐 아니라 PDF, 엑셀, URL 등 다양하게 적용 가능합니다.)를 로딩해옵니다.
로딩해온 긴 문서를 작은 덩어리(청크)단위로 쪼갭니다.
쪼개진 덩어리를 임베딩하여 벡터 데이터로 변환(벡터화)합니다.
임베딩? 벡터화의 일종으로, 텍스트 데이터를 컴퓨터가 이해할 수 있는 벡터로 변환하여 의미론적 정보를 유지하는 과정 => 단어 간 유사성을 반영
벡터화? 텍스트 데이터를 숫자 벡터로 변환하는 일반적인 과정
벡터화가 임베딩보다 일반적이고 넓은 의미이지만, 보통 딥러닝 과정에서는 두 용어를 동의어처럼 사용하기도 합니다.
벡터화된 데이터를 벡터 저장소(스토어)에 저장합니다.
사용자가 입력한 질문을 벡터화합니다.
벡터화된 질문을 벡터 저장소에 전달합니다.
전달받은 질문을 통해 벡터 저장소에서 유사도 검색을 수행하여, 질문과 관련된 문서를 반환합니다.
사용자로부터 입력받은 질문과 반환된 관련 문서로 프롬프트를 생성하여 LLM에게 입력하여 생성된 답변을 얻습니다.
최종적으로 LLM으로부터 출력받은 응답을 사용자에게 전달해줍니다.
RAG 수행을 위한 lancghain 모듈
RAG 수행을 위한 Retrieval 모듈들에 대한 langchain 공식 문서입니다.
- https://js.langchain.com/v0.1/docs/modules/data_connection/
LangChain은 앞서 설명한 RAG 응용 프로그램에 필요한 모든 구성 요소를 제공합니다.
문서 로더 Document loaders
다양한 소스에서 문서를 로드합니다. LangChain은 Unstructured와 같은 주요 공급업체와의 통합을 포함하여 여러 문서 로더를 제공합니다. HTML, PDF, 코드와 같은 모든 유형의 문서를 로드할 수 있습니다.
텍스트 분할 Text Splitting
검색의 중요한 부분은 문서의 관련 부분만 가져오는 것입니다. 이는 문서를 검색에 가장 잘 준비하기 위해 여러 변환 단계를 포함합니다. 주요 방법 중 하나는 큰 문서를 작은 조각으로 나누는 것입니다. LangChain은 이를 수행하기 위한 여러 알고리즘과 특정 문서 유형에 최적화된 로직을 제공합니다.
텍스트 임베딩 모델 Text embedding models
검색의 또 다른 중요한 부분은 문서에 대한 임베딩을 생성하는 것입니다. 임베딩은 텍스트의 의미를 포착하여 유사한 다른 텍스트를 빠르고 효율적으로 찾을 수 있게 합니다. LangChain은 다양한 임베딩 제공업체 및 방법과의 통합을 제공하며, 이를 통해 필요에 가장 적합한 것을 선택할 수 있습니다. LangChain은 표준 인터페이스를 제공하여 모델 간 쉽게 전환할 수 있습니다.
벡터 저장소 Vector stores
임베딩의 증가와 함께 이러한 임베딩을 효율적으로 저장하고 검색할 수 있는 데이터베이스에 대한 필요성이 대두되었습니다. LangChain은 오픈 소스 로컬 저장소에서 클라우드 호스팅된 독점 저장소에 이르기까지 다양한 벡터 저장소와의 통합을 제공하여 필요에 가장 적합한 것을 선택할 수 있습니다. LangChain은 표준 인터페이스를 제공하여 벡터 저장소 간 쉽게 전환할 수 있습니다.
리트리버 Retrievers
데이터가 데이터베이스에 저장된 후에도 이를 검색해야 합니다. LangChain은 여러 검색 알고리즘을 지원하며, 여기서 가장 큰 가치를 제공합니다. 간단한 시맨틱 검색 방법부터 성능을 높이기 위한 여러 알고리즘을 추가했습니다. 여기에는 다음이 포함됩니다:
상위 문서 리트리버: 상위 문서당 여러 임베딩을 생성하여 더 작은 조각을 검색하지만 더 큰 문맥을 반환할 수 있습니다.
자체 쿼리 리트리버: 사용자 질문에는 시맨틱한 것뿐만 아니라 메타데이터 필터로 가장 잘 표현될 수 있는 논리를 포함하는 경우가 많습니다. 자체 쿼리는 쿼리에서 시맨틱한 부분과 기타 메타데이터 필터를 구분할 수 있습니다.
기타: 더 많은 알고리즘이 포함됩니다.
(참고) langchain 에서의 RAG 아키텍쳐
✏️ Wrap up!
이번 챕터에서는 기존 LLM이 가지고 있던 한계인 특정 데이터를 기반으로 한 답변 생성을 할 수 있는 방식은 RAG에 대해 살펴보았습니다. Langchain에서는 이를 구현하기 위한 과정들에서 각 모듈들을 제공하고 있어 모듈들의 종류에 대해서도 간단히 살펴보았습니다.
다음 챕터에서는 이번 챕터에서 자세히 다루지 않았던 벡터 저장소에 대해 알아보도록 하겠습니다. 또한 벡터 유사도 검색을 RAG를 통해 통합하는 과정에 대해 배우며, Langchain의 어떤 모듈들이 단계 별로 사용되는지 알아봅시다.
이번 챕터와 다음 챕터에서는 개념 위주의 이야기를 다룰 예정입니다. 개념을 익히고 전체적인 그림을 그려본 후에, 실제로 langchain에서 제공하는 모듈들을 이용하며 RAG를 구현하는 각 과정들에 대한 챕터를 진행보도록 하겠습니다 :) !