Langchain Study | 3-1. Model I/O
이번 챕터에서는 Langchain의 모듈 중 가장 필수적이고 많이 쓰이는 Model I/O 모듈에 대해 알아봅시다.
1장에서 다뤘던 간단한 LLM 어플리케이션의 아키텍쳐 그림을 다시 살펴봅시다.
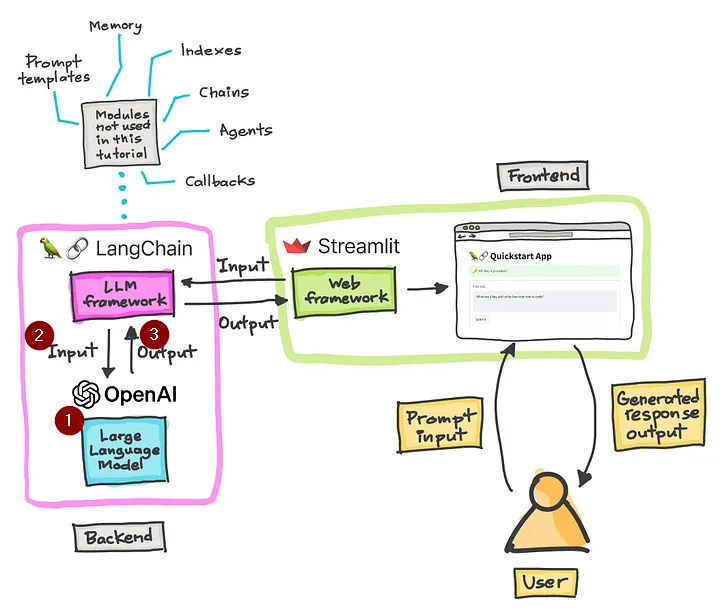
위 아키텍쳐에서 숫자를 매긴 부분에 대한 동작은 아래와 같이 이루어집니다. Langchain의 Model I/O는 아래의 모듈로 구성됩니다.
LLM을 프레임워크와 연동합니다. => Language models
사용자로부터 질문을 입력받아 LLM 모델에 전달해줍니다. => Prompts
LLM 모델로부터 응답받은 결과값을 받아 다시 사용자에게 전달합니다. => Output Parsers
Model I/O의 아키텍쳐입니다.
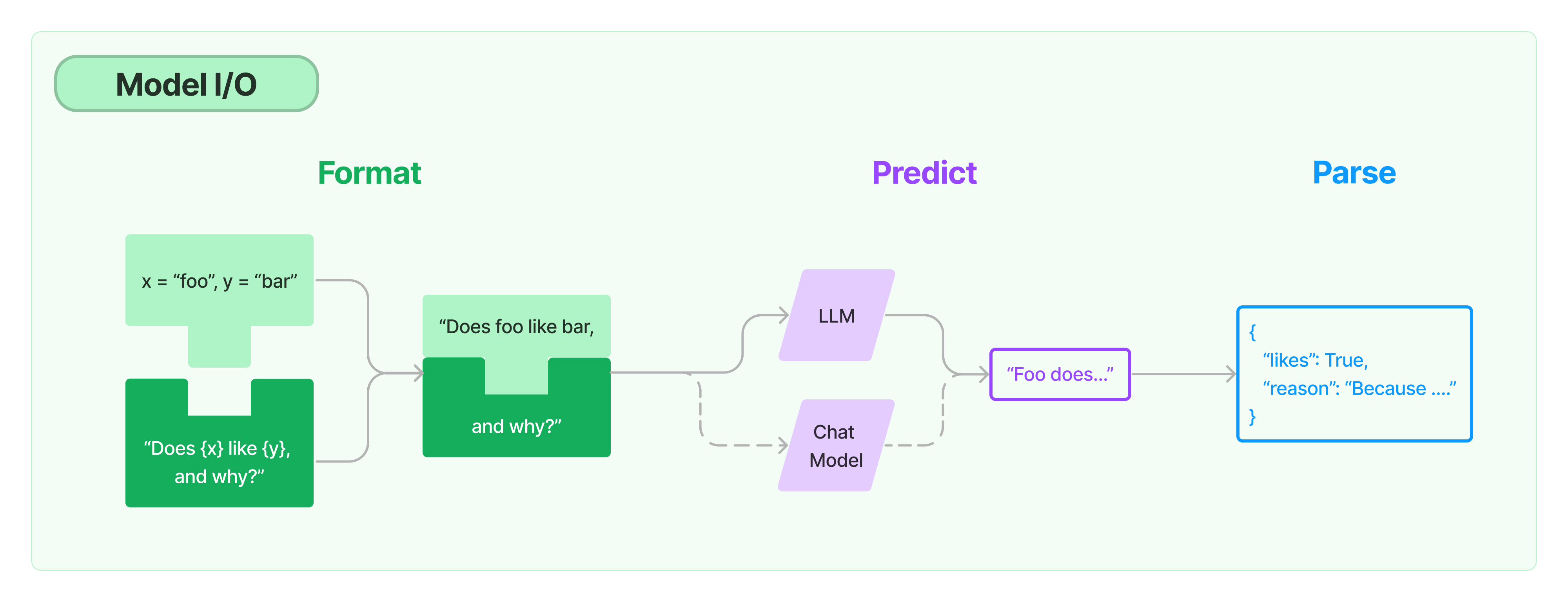
정해진 Format에 따라 Prompt를 생성하고, 연동된 Model에 질문으로 전달하면 응답을 받아서, 사용자가 원하는 형식으로 파싱하여 결과를 전달받는 과정입니다.
langhchain 공식 홈페이지에서의 Model I/O에 대한 자료는 아래의 링크에서 확인할 수 있습니다.
https://js.langchain.com/v0.1/docs/modules/model_io/
Model I/O의 세 가지 모듈을 각 각 좀 더 자세히 볼까요?
Language models
Language models 모듈은 다양한 언어 모델을 동일한 인터페이스에서 호출할 수 있는 기능을 제공합니다. 위 예제에서는 openAI의 chatGPT를 사용했으나, 다른 코드 변환 없이 모델을 호출해주는 부분에서 huggingface 등의 다른 모델명을 작성하면 다른 모델을 호출 할 수 있습니다. 이를 통해 다른 모델에 대한 테스트 시, 매우 간편하게 모델을 변경할 수 있습니다.
01_model.py
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain.chat_models import ChatOpenAI #← 모듈 가져오기
from langchain.schema import HumanMessage #← 사용자의 메시지인 HumanMessage 가져오기
chat = ChatOpenAI( #← 클라이언트를 만들고 chat에 저장
model="gpt-3.5-turbo", #← 호출할 모델 지정
)
result = chat( #← 실행하기
[
HumanMessage(content="안녕하세요!"),
]
)
print(result.content)
위 소스코드는 OpenAI의 gpt-3.5-turbo 모델에 안녕하세요! 라는 프롬프트(질문)을 전송한 후 결과를 받아온 과정을 수행합니다.
Message Types
ChatModel의 경우에는 메시지의 목록을 입력받아 답변을 생성해줍니다. 메시지는 몇 개의 타입이 있습니다. 모든 메시지는 role과 content를 가지고있어요.
role: 메시지를 누가 말하는지 => 랭체인은 role별로 다른 클래스를 제공합니다.content: 메시지의 내용
HumanMessage- 사용자로부터 오는 메시지를 나타냅니다.
- 일반적으로 내용만 포함됩니다.
AIMessage- 모델로부터 오는 메시지를 나타냅니다. 이는 추가적인 인자를 포함할 수 있습니다.
SystemMessage- 시스템 메시지를 나타내며, 모델의 동작 방식을 지시합니다.
- 일반적으로 내용만을 포함합니다. 모든 모델이 이를 지원하는 것은 아닙니다.
FunctionMessage- 함수 호출의 결과를 나타내는 메시지입니다.
- 역할과 내용 외에도, 이 메시지는 결과를 생성한 함수의 이름을 전달하는 name 매개변수를 가지고 있습니다.
ToolMessage- 도구 호출의 결과를 나타내는 메시지로, FunctionMessage와 구분됩니다.
- OpenAI의 함수 및 도구 메시지 유형에 맞추기 위한 것입니다.
- 역할과 내용 외에도, 이 메시지는 결과를 생성한 도구 호출의 ID를 전달하는 tool_call_id 매개변수를 가지고 있습니다.
LLM Parameters
LLM을 호출할 때는 위와 같이 단순히 모델명만 지정해서 호출해줄 수도 있지만, 여러 파라미터들을 이용해서 설정을 추가해줄 수 있습니다.
01_model_param.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from langchain.chat_models import ChatOpenAI # ← 모듈 가져오기
from langchain.schema import HumanMessage # ← 사용자의 메시지인 HumanMessage 가져오기
chat = ChatOpenAI( # ← 클라이언트를 만들고 chat에 저장
model="gpt-3.5-turbo", # ← 호출할 모델 지정
temperature=1,
max_tokens=256,
model_kwargs={"top_p": 0.5,
"frequency_penalty": 0,
"presence_penalty": 0
},
)
result = chat( # ← 실행하기
[
HumanMessage(content="여름에 대해 설명해줘"),
]
)
print(result.content)
위 예제에서는 OpenAI의 Chat모델을 사용할 때, temperature, top_p, max_tokens 등의 설정을 추가해준 코드입니다.
각 파라미터의 의미는 다음과 같습니다.
temperature: 출력 텍스트의 창의성 수준을 조절하는 값- 값이 높을수록 출력이 더 다양하고 창의적이 되며, 값이 낮을수록 출력이 더 일관되고 예측 가능
- 즉, Temperature는 모델의 출력을 얼마나 “무작위”로 만들지를 조절하는 값
max_tokens: 생성할 응답의 최대 토큰 수 지정- 한 토큰은 단어나 문자 등의 기본 단위
top_p: 출력 텍스트의 다양성을 제어하는 파라미터- 즉, 단어를 선택할 때 확률이 높은 상위 p%의 단어들만 고려하도록 하는 방법
- 값이 높을수록 빈도(확률)이 높은 토큰들만을 선택 => 응답 다양성이 증가
- 값이 낮을수록 빈도(확률)이 낮은 토큰들만을 선택 => 더 예측 가능한 응답
frequency_penalty: 같은 단어의 반복 사용을 얼마나 억제할지를 결정하는 값presence_penalty: 새로운 단어를 도입하는 것을 얼마나 장려할지를 결정하는 값
temperature와 top_p는 응답의 창의성/다양성을 제어한다는 점에서 유사한 역할을 하는 것처럼 보이는데요, 자세한 두 파라미터의 차이에 대해 더 알고싶으시다면 LLM 모델의 파라미터 - Temperature와 Top-P을 참고해보세요 :)
Prompts
위 예제 소스코드에서는 안녕하세요!라는 프롬프트를 직접 작성했지만, 용도에 따라 다양한 템플릿을 적용하여 프롬프트를 전송할 수 있습니다. 다양한 처리를 통해 원하는 프롬프트를 쉽게 만들 수 있도록 하는 것이 목적입니다.
PromptTemplate
예시를 들어 설명을 드릴게요. 만약 저는 어떤 회사에서 개발한 제품인지를 알려주는 어플리케이션을 개발하는 것이 목적입니다. 사용자가 제품명을 입력하면, 프로그램에서 LLM에 해당 제품명의 개발 회사에 대해 질문하고, 다시 LLM이 어느 회사인지 답변해주면 그 답변을 사용자에게 전달하는 서비스입니다.
그때 저는 {product}는 어느 회사에서 개발한 제품인가요? 라는 질문의 형식을 매번 똑같이 LLM에 던질 것이기 때문에 템플릿으로 사용합니다. 이 때 사용할 수 있는 것이 Prompts 모듈이며 해당 서비스를 구현한 소스코드는 아래와 같습니다.
02_prompt.py ```python from langchain import PromptTemplate from langchain.chat_models import ChatOpenAI from langchain.schema import HumanMessage
chat = ChatOpenAI( #← 클라이언트 생성 및 chat에 저장 model=”gpt-3.5-turbo”, #← 호출할 모델 지정 )
prompt = PromptTemplate( #← PromptTemplate을 작성 template=”{product}는 어느 회사에서 개발한 제품인가요?”, #← {product}라는 변수를 포함하는 프롬프트 작성하기 input_variables=[ “product” #← product에 입력할 변수 지정 ] )
result = chat( #← 실행 [ HumanMessage(content=prompt.format(product=”아이폰”)), ] ) print(result.content)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
기존에는 HumanMessage에 직접 질문을 작성했으나, prompt를 이용하여 특정 단어만 입력 받아도 문장으로 완성하여 질문이 전달될 수 있습니다.
#### ChatPromptTemplate
위에서는 가장 기본적인 Prompt Template인 `PromptTemplate`을 사용해보았는데요,
대화 메시지의 목록을 프롬프트로 작성하는 `ChatPromptTemplate`도 많이 사용되는 라이브러리입니다.
> 02_prompt-2.py
```python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI( # ← 클라이언트 생성 및 chat에 저장
model="gpt-3.5-turbo", # ← 호출할 모델 지정
)
chat_prompt = ChatPromptTemplate.from_messages( # ← ChatPromptTemplate 작성
[
("system", "{talker}가 {listner}에게 말하듯 대답해주세요."),
("human", "{user_input}")
]
)
result = chat( # ← 실행
chat_prompt.format_messages(talker="유치원 선생님", listner="어린이", user_input="안녕하세요?")
)
print(result.content)
# 안녕하세요! 반가워요! 무엇을 도와드릴까요? 😊
ChatPromptTemplate를 통해 SystemMessage, HumanMessage, AIMessage등 다양한 Message 스키마에 대한 프롬프트 템플릿을 구현하는 것도 가능합니다.
Output Parsers
Output parsers 모듈은 언어 모델에서 얻은 출력을 분석해서 어플리케이션에서 사용하기 쉬운 형태로 변환하는 기능을 제공합니다. 출력 문자열을 정형화하거나 특정 정보를 추출하는데 사용합니다. 이 모듈을 통해서 출력을 구조화된 데이터로 쉽게 처리할 수 있습니다.
기존에 존재하는 output parsers 모듈을 사용할 수도 있고, 개인적으로 커스터마이징한 모듈을 적용하여 사용할 수도 있습니다.
Basic
먼저 기존에 존재하는 output parser 모듈 적용 사례를 살펴보겠습니다.
CommaSeparatedListOutputParser 를 이용한 목록형식으로 결과 받기 (list_output_parser.py)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import \
CommaSeparatedListOutputParser #← Output Parser인 CommaSeparatedListOutputParser를 가져옵니다.
from langchain.schema import HumanMessage
output_parser = CommaSeparatedListOutputParser() #← CommaSeparatedListOutputParser 초기화
chat = ChatOpenAI(model="gpt-3.5-turbo", )
result = chat(
[
HumanMessage(content="애플이 개발한 대표적인 제품 3개를 알려주세요"),
# output_parser.get_format_instructions()를 실행하여 언어모델에 지시사항 추가하기
# => prompt에 응답을 콤마로 구분된 목록형식으로 달라는 지시사항 추가
HumanMessage(content=output_parser.get_format_instructions()),
]
)
# result.content : 아이폰, 아이패드, 맥북
output = output_parser.parse(result.content) #← 출력 결과를 분석하여 목록 형식으로 변환한다.
# output: ['아이폰', '아이패드', '맥북']
CommaSeparatedListOutputParser는 결과를 목록 형태로 받아 출력합니다.
목록 형식으로 출력하도록 언어 모델에 출력 형식 지시를 추가한다.
출력 결과를 분석해 목록 형식으로 변환한다.
즉, 프롬프트에 질문을 줄 때 단순히 애플이 개발한 대표적인 제품 3개를 알려주세요이 말만 하는 것이 아니라 output_parser.get_format_instructions()를 통해 콤마로 구분된 목록 형식으로 달라는 지시를 같이 하는 것입니다.
그로 인해 LLM으로부터 다음의 응답을 받습니다. => 아이폰, 아이패드, 맥북
해당 응답을 다시 output_parser.parse(result.content)을 통해 output을 python의 배열 형태로 변환하여 반환받습니다.
CommaSeparatedListOutputParser외에도 날짜형식으로 출력받기 등의 기본 output parser들이 존재합니다.
Custom
하지만 우리가 특정한 구조를 가진 output 타입을 받고싶을 때도 있습니다. 그럴 경우 출력 형식을 직접 정의하는 방법도 있습니다.
스마트폰에 대해 질문했을 떄, 해당 스마트폰에 대한 정보를 SmartPhone이라는 클래스로 출력받는 output parser를 만들어봅시다. SmartPhone 클래스에는 release_date, screen_inches, os_installed, model_name 요소가 존재합니다.
출력 형식을 직접 정의하여 결과 받기 (04_pydantic_output_parser_1.py)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.schema import HumanMessage
from pydantic import BaseModel, Field, validator
chat = ChatOpenAI()
class Smartphone(BaseModel): #← Pydantic의 모델을 정의한다.
release_date: str = Field(description="스마트폰 출시일") #← Field를 사용해 설명을 추가
screen_inches: float = Field(description="스마트폰의 화면 크기(인치)")
os_installed: str = Field(description="스마트폰에 설치된 OS")
model_name: str = Field(description="스마트폰 모델명")
@validator("screen_inches") #← validator를 사용해 값을 검증
def validate_screen_inches(cls, field): #← 검증할 필드와 값을 validator의 인수로 전달
if field <= 0: #← screen_inches가 0 이하인 경우 에러를 반환
raise ValueError("Screen inches must be a positive number")
return field
parser = PydanticOutputParser(pydantic_object=Smartphone) #← PydanticOutputParser를 SmartPhone 모델로 초기화
result = chat([ #← Chat models에 HumanMessage를 전달해 문장을 생성
HumanMessage(content="안드로이드 스마트폰 1개를 소개해주세요."),
HumanMessage(content=parser.get_format_instructions()) # <- prompt에 outputparser class에 정의한 내용 추가
])
print(f"응답에서 output parsing 적용 전 => {result.content}")
# 응답에서 output parsing 적용 전 => {
# "release_date": "2021-09-15",
# "screen_inches": 6.4,
# "os_installed": "Android 11",
# "model_name": "Samsung Galaxy S21 Ultra"
# }
parsed_result = parser.parse(result.content) #← PydanticOutputParser를 사용해 문장을 파싱
print(f"응답에서 output parsing 적용 후 => {type(parsed_result)}")
# 응답에서 output parsing 적용 후 => <class '__main__.Smartphone'>
print(f"모델명: {parsed_result.model_name}") # 모델명: Samsung Galaxy S21 Ultra
print(f"화면 크기: {parsed_result.screen_inches}인치")# 화면 크기: 6.4인치
print(f"OS: {parsed_result.os_installed}") # OS: Android 11
print(f"스마트폰 출시일: {parsed_result.release_date}") # 스마트폰 출시일: 2021-09-15
여기서는 PydanticOutputParser를 통해 직접 정의한 output parser를 적용합니다.
💡참고
- Pydantic 모델은 파이썬에서 데이터 검증을 위한 라이브러리로, 타입 힌드틀 이용해 데이터 모델을 정의하고 이를 기반으로 데이터 분석과 검증을 수행하는 도구입니다.
PydanticOutputParser을 사용하면 아래와 같은 것들이 가능합니다.
개발자가 명시적으로 유연하게 데이터 구조를 정의할 수 있고, 이에 따라 분석 결과를 맞출 수 있다.
모델 검증 기능을 활용해 파싱된 데이터의 무결성을 보장할 수 있다.
파싱 결과를 파이썬 객체로 쉽게 가져와 후속 처리에 활용한다.
위 코드에서는 Smartphone 이라는 클래스에 각 필드를 정의하고, 타입 힌트를 사용해 정의합니다. 또한 validator를 사용해서 화면 크기가 0 이상인지에 대한 검증도 추가했습니다. (만약 검증에서 오류가 발생하면, 다시 프롬프트를 작성하여 LLM에 질문합니다.)
위 코드가 돌아가는 방식은 다음과 같습니다.
Smartphone이라는 클래스에 각 필드를 타입 힌트를 사용해 정의한다. 또한 설명을 추가한다.validator를 사용해서 화면 크기가 0 이상인지에 대한 검증도 추가한다.
LLM에 질문과 생성한 output parser을 함께 프롬프트로 전달한다.
LLM은 질문을 받고, 정의된 output parser의 형식에 맞춰 답변을 생성한다.
이때 만약 output parser 검증(validator)에 따라 오류가 발생하는 답변이 생성된 경우 다시 재질문하여 오류가 없는 답변을 재생성한다.
LLM에서 받은 응답은
Smartphone클래스 객체의 형태로 받는다.각 객체의 값들을 획득하여 응답으로 활용할 수 있다.
✏️ Wrap up!
이번 챕터에서는 랭체인의 가장 기본적인 모듈인 Model I/O의 세 가지 모듈 (Prompts, Language Model, Output Parsers)에 대해 간단한 예시를 살펴보았습니다.
오늘 본 예제들은 아주 단편적이고 기초적 예제에 불과합니다. Language Model에서도 캐싱, 스트리밍 등 여러 확장성 있는 모듈을 붙일 수 있습니다. 하지만 Model I/O는 langchain에서 가장 기본이 되는 모듈이기 때문에, 앞으로 다른 예제들을 사용하며 추가적으로 적용해보고자 합니다.
다음 챕터에서는 Retrieval 모듈에 대해 살펴보기 앞서, RAG의 구조와 개념에 대해 알아봅시다!